gpu核心结构
本文最后更新于 2023年9月10日 下午
本篇是《通用图形处理器设计-GPGPU编程模型与架构原理》的阅读笔记
基础
在上面已经提到线程块调度器会将线程块发送给对应的处理器,而处理器将执行线程块中所有线程。但是线程网格和线程块都是用户指定的,而硬件资源是有限的,例如寄存器端口,执行单元数量等。如果线程块的数量过大,那么执行一条指令就需要很多周期的时间,而且不好调度。因此处理器中真正的调度单位是线程束,线程束的大小是根据硬件资源决定的,线程块传递给处理器时会自动将线程块划分成若干线程束。
线程束中所有线程的pc相同,即执行的指令相同,不同的是他们有不同的线程id,读寄存器时会根据线程id和寄存器id来获得寄存器值。如果将它看成向量处理器,那么线程束就是单个指令流,每个线程只是一个分量。
每一个处理器中都会同时存在大量线程束,通过快速切换线程束执行来隐藏访存等耗时操作的延迟。
GPU指令流水线
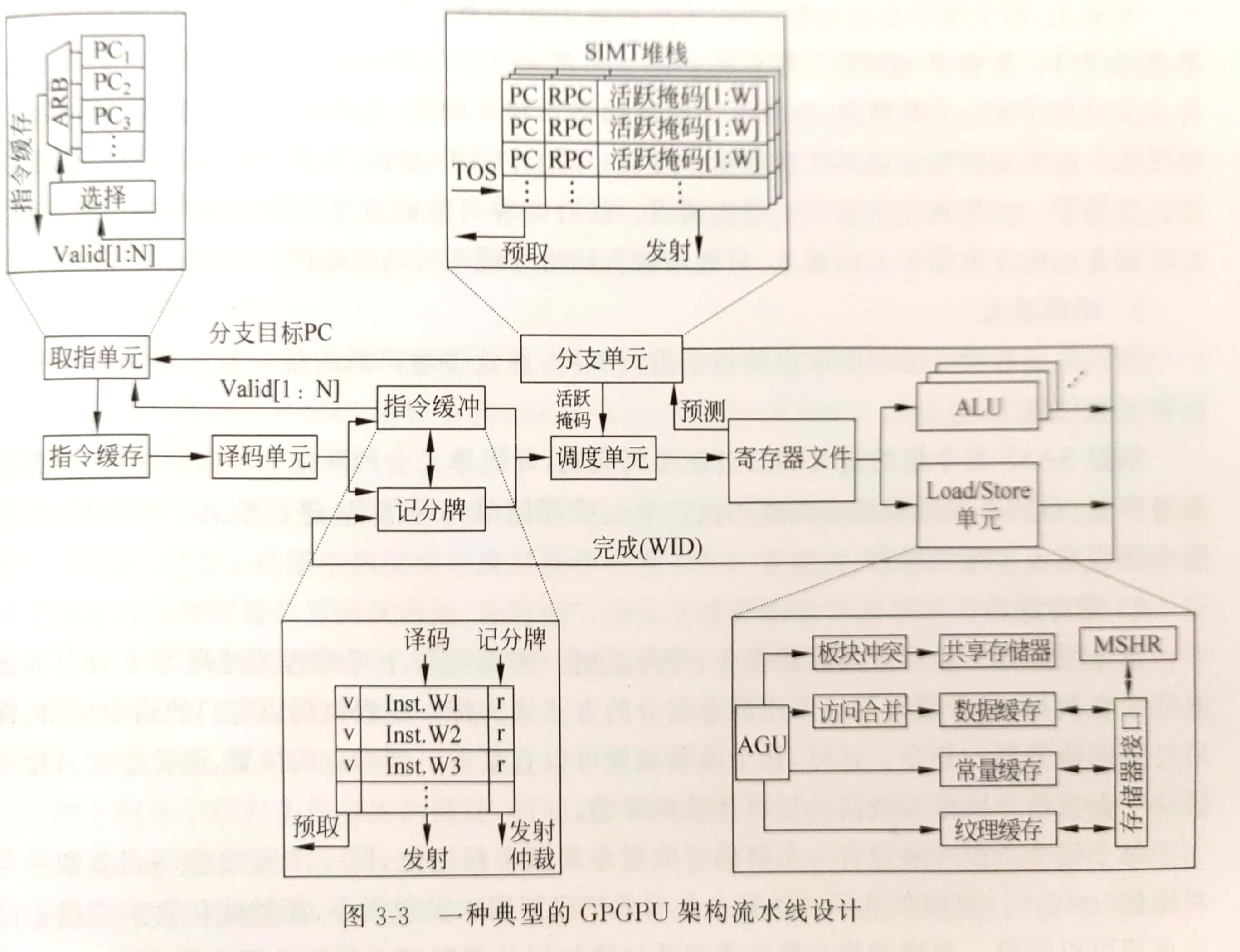
gpu流水线和cpu类似,分为取指,译码,调度,读寄存器,执行,写回等阶段。
取指和译码
在gpu中由于同时存在多个线程束且每个线程束的执行进度不一致,因此取指单元中需要保存多个pc值,然后调度单元根据线程束的状态选取一个进行执行。
指令缓存用于缓存接收到指令的pc,也就是超标量处理器中使用的InstBuffer。
指令缓冲用于缓存译码后的指令,包含源寄存器,目的寄存器等。计分牌用于判断当前寄存器是否准备完成,当指令中所有寄存器都准备完成之后就可以发射进行下一步操作。
调度
调度单元通过线程束控制器来控制指令缓冲中准备就绪的线程束进行发射。检查包括数据相关,执行单元空闲,是否在等待同步栅栏等。
记分牌用于检查指令间可能存在的相关性依赖。例如写后写或写后读。计分牌算法会记录每一个寄存器状态,发射出去的指令的目的寄存器会被置0,直到该指令写回后才会重新置1。置0表示当前寄存器值不可信,需要等待。
执行和写回
GPU为每个处理器提供了许多alu单元,用于算术逻辑类指令的执行。某些指令需要在特殊功能单元(Special Function Unit SFU)上执行,例如平方根和超越函数。这些指令的数量不会很多,所以往往多个核共享一个功能单元,如果大量执行这些指令,吞吐率就会大为下降。
存储访问单元负责访存指令的处理。存储访问单元会和共享存储器,L1数据缓存,常亮缓存和纹理缓存进行交互。它包括地址生成单元,冲突处理,地址合并,MSHR等单元来提高访问速度。
线程分支
例如:
1 | |
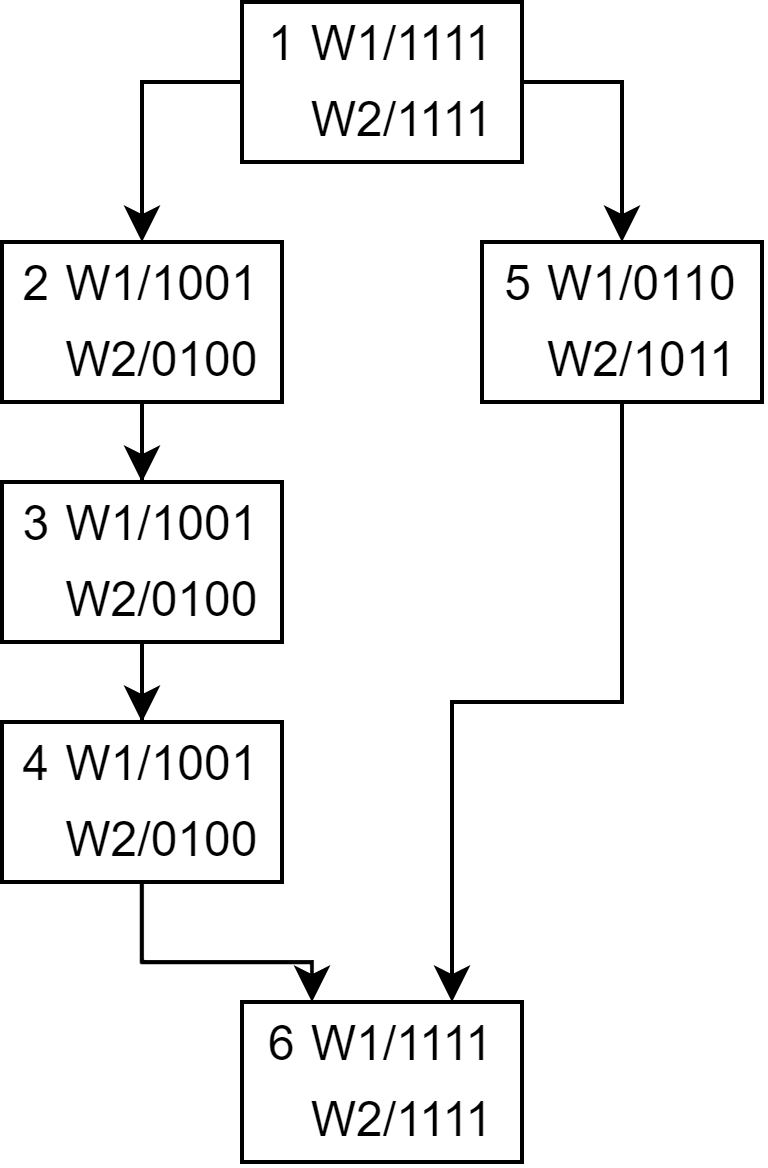
假设现在有一个包含4个线程的线程束要执行这段代码,历程如图所示
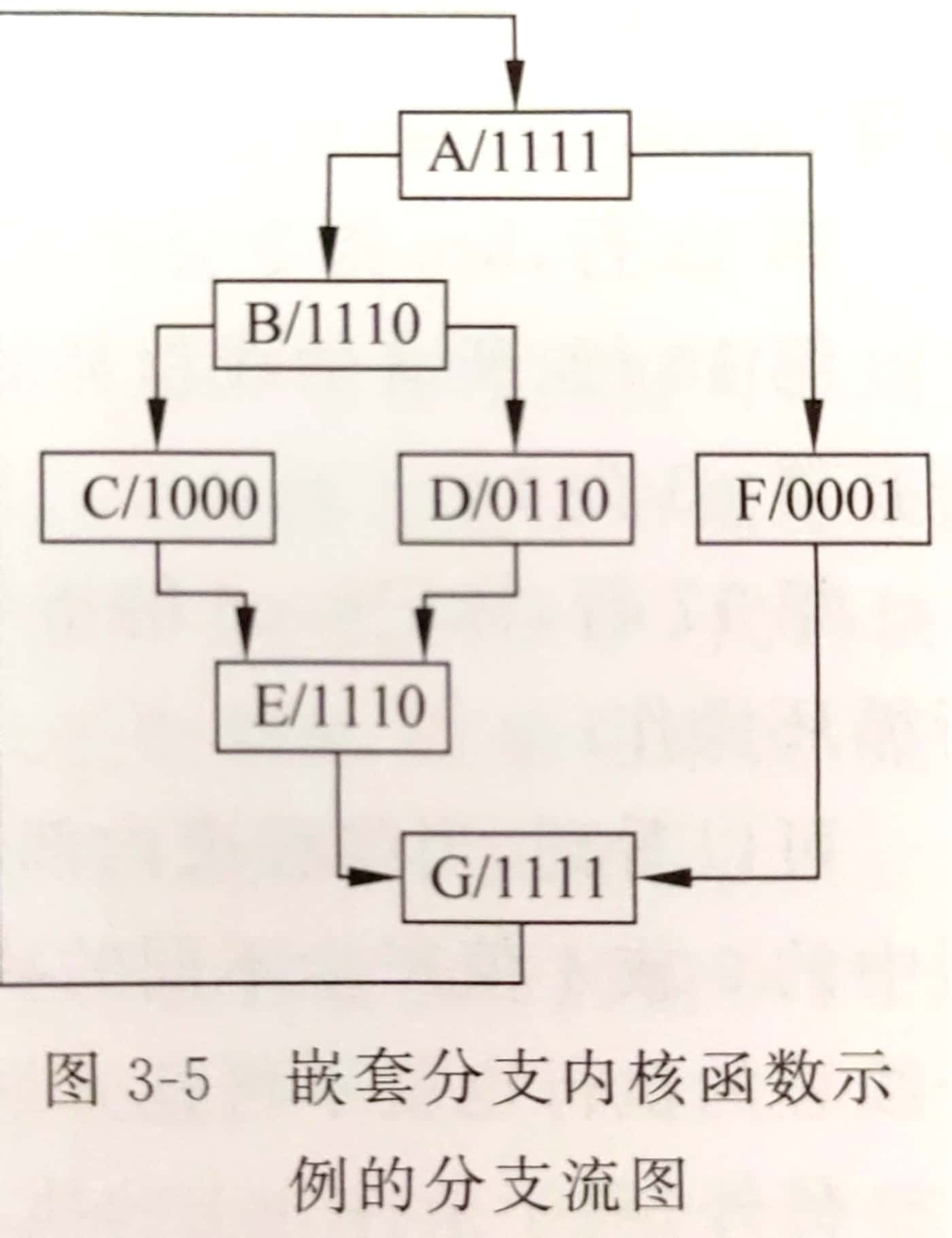
SIMT堆栈
要理清楚上面的分支如何运作,首先需要了解SIMT堆栈的运作方式。SIMT堆栈实现了活跃掩码的管理和指令流的管理,
gpu中的处理器一次只能执行一条指令,而如果遇到了分支指令,一部分线程需要执行if的部分,另外一部分线程执行else的部分,这样便形成了多指令流。因此经过分支指令之后,我们先要让一部分线程执行if部分,等待if部分全部执行完成再切换掩码和pc让else部分执行完成。因此当我们执行if部分时需要保存else的掩码和pc,这便是SIMT堆栈所要完成的事。
SIMT堆栈本质上就是一个栈,栈顶指针(TOS)指向最上面的条目,每个条目包含三个字段
- RPC: 分支指令的if和else部分执行完成之后汇聚的位置。这个字段是为了执行完if或else之后可以顺利切换到其他指令流。这是通过编译器获得的
- NPC: 下一条指令的pc
- Active Mask: 线程活跃掩码
现在就可以通过SIMT堆栈解释上面代码的执行过程了,初始SIMT堆栈状态为:
| RPC | NPC | 活跃掩码 |
|---|---|---|
| / | G | 1111 |
在执行到B时活跃掩码变为:
| RPC | NPC | 活跃掩码 |
|---|---|---|
| / | G | 1111 |
| G | F | 0001 |
| G | B | 1110 |
当B执行到C后,他们的重聚点为E,因此活跃掩码为:
| PRC | NPC | 活跃掩码 |
|---|---|---|
| / | G | 1111 |
| G | F | 0001 |
| G | E | 1110 |
| E | D | 0110 |
| E | C | 1000 |
注意G/B/1110要变为G/E/1110,因为它分出了两条指令流,然后这两条指令流代替它接下来的执行,直到到了重聚点之后才又切换成该指令的执行。
到了这一步之后执行C,C到E之后RPC==NPC, 将这一项弹出栈。然后切换掩码为0110,pc为D继续执行,D执行到E之后再弹栈,切换掩码为1110,pc为E来执行。
分支屏障
SIMT堆栈可能会导致死锁,下面是一个例子:
1 | |
例如一个线程束中四个线程同时执行atomicCAS(原子交换)指令,那么只有一个线程可以获得锁,其他三个线程都在等待获得锁的线程释放锁。但是此时SIMT堆栈的栈顶是指向剩下三个线程的,因此便导致了死锁。
上述问题其实很好解决。让这三个线程将执行权先放弃,让获得锁的线程先执行直到释放锁,那么便可以顺利的执行了。
为此设计了三条指令,ADD,WAIT和Yield:
- ADD: 给线程设定屏障编号
- WAIT: 设定屏障的线程进入等待,直到所有设定屏障的线程执行到WAIT才可继续执行
- Yield:让线程进入让步状态,
线程动态重组及合并
线程分支会极大的降低硬件利用率,不同线程束可能会执行相同的指令,如果将不同线程束之间的指令流进行合并就可以提高避免分支带来的性能损失。
例如,假如有8个线程分成两个线程束,然后假设这两个线程束执行了一个分支指令导致两个线程执行if部分,两个线程执行else部分。如果能将这两个线程束中的线程重组为一个线程便可再次满载运行。
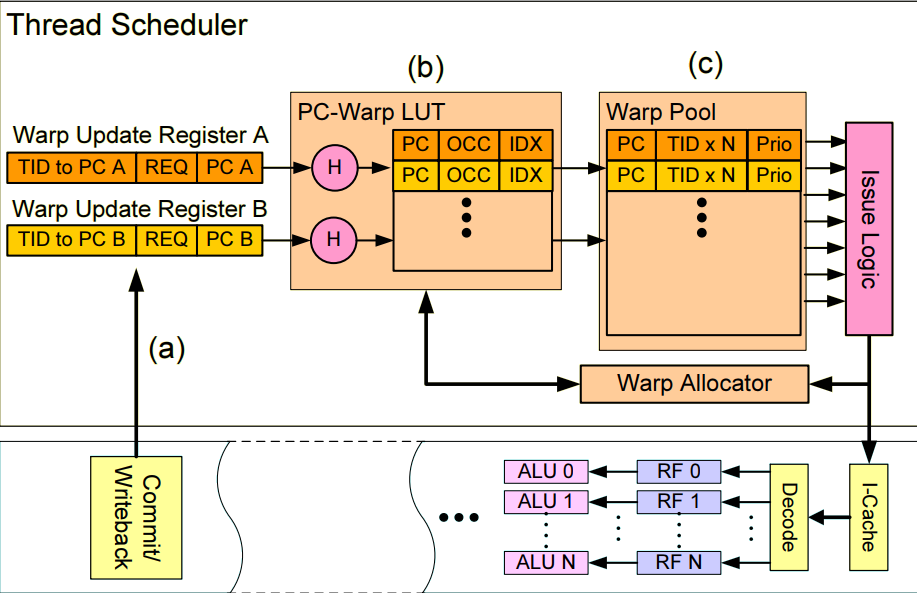
上图为一种不同线程束同PC线程之间合并的方法[1]
它添加了PC-Warp LUT来管理pc和线程束之间的映射关系,然后使用线程束池来管理合并之后的线程束,此处PC-Warp LUT中的IDX项指向的是线程池中的位置。
为了支持原位合并,文献[2]中提出了基于原有SIMT堆栈的实现方法,称为线程块压缩。为此调度器需要维护一个和SIMT堆栈相似的结构,用于维护一个线程块内多个线程束的指令流。栈中每项包含四个元素:
- RPC,NPC:和SIMT堆栈中含义相同
- Active Mask: 这里的活跃掩码是一个线程块中所有线程的,而不单单一个线程束的
- WCnt:当前指令流活跃线程束的数量,如果活跃数量大于1表示这两个线程束的指令流可以合并
此外, 文献[3]中提出了一种基于大线程束的线程重组策略。
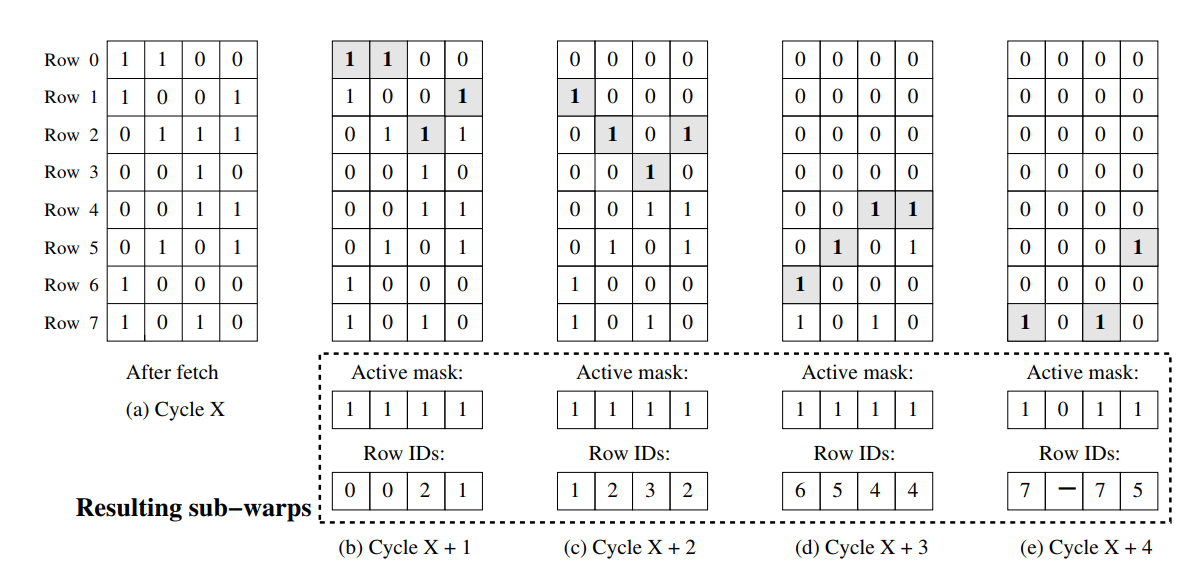
如图所示为大线程束的组织形式,大线程束由若干线程束组成,上图每一列表示一个指令流,每一行是指令流中的活跃掩码。大线程束仍由RPC和NPC,每次遇到分支指令时会创建两个新的大线程束或者融入已有的大线程束。大线程束每次执行时会从每一列挑选一个活跃线程组成线程束送入执行单元中,此时访存方式不再是(线程束id, 线程id),而是(大线程束id, 行号, 线程id)
这种方式虽然看起来很理想,但也会引入一些其他问题,例如:
- 当新线程束访问寄存器时,要避免线程错位方位或多个线程访问寄存器带来的冲突
- 会导致线程之间的同步问题
- 可能导致更多的告诉缓存缺失,因为现在同时执行多个线程束中的线程,数据的空间局部性不如原来理想
同线程束不同pc之间的重组
这种情况下主要依赖于分支路径上往往存在互补性,即分支分叉之后,true路径和false路径线程存在互补性。但是这种情况比同pc之间的合并更加困难,因为执行了不同的指令,更类似于MIMD的运行。
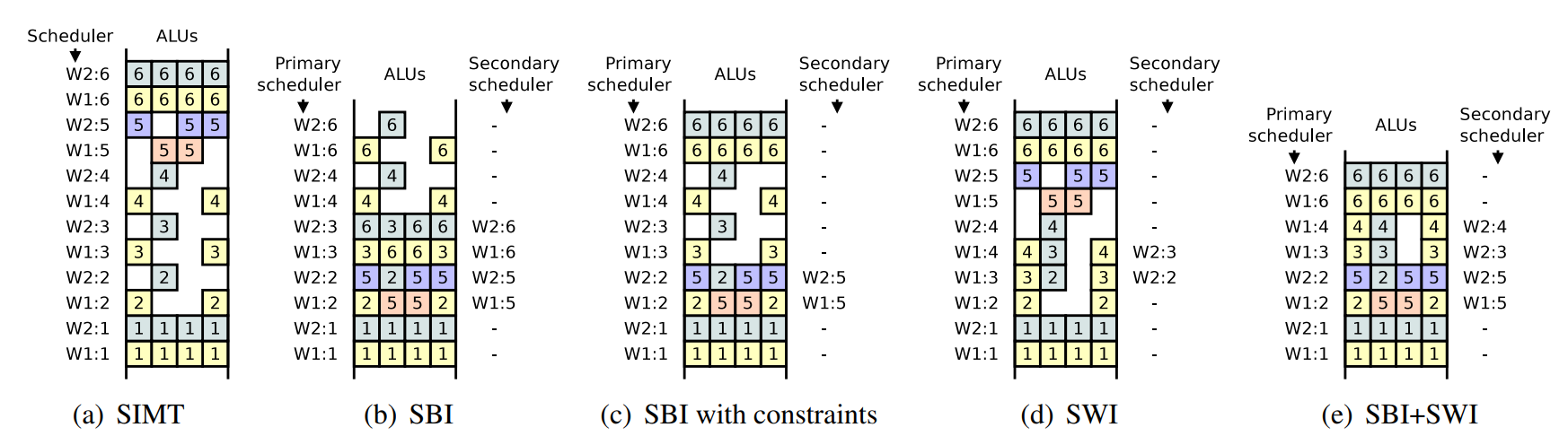
文献[4]提出了上述情况的一种实现方式,称为SBI。它使用了主次两个调度器。其中副调度器接收主调度器的线程束id来跟随发射某个线程束的指令。
 |
 |
|---|---|
如图所示为SBI和传统SIMT调度的区别,注意是执行顺序是从下至上。SBI的第三次调度时除了调度了指令流2,还通过副调度器调度了互补的指令流5。
但是SBI如果没有遇到资源冲突就会一直执行,例如第5次调度时W1提前执行了重聚点6的指令,这会导致重聚点推迟。针对这一问题,可以对SBI进行限制,例如不允许分支点和重聚点的指令参与线程重组。
不同线程束之间不同PC的重组合并
不同线程束之间重组和相同线程束之间重组的思想类似,也是通过副调度器发现并行的可能性。
线程束调度
gpu线程调度器的职责是从就绪的线程束中挑选一个或多个线程束发送给空闲的执行单元。
线程束暂时不能发射的原因有:
- Pipeline busy: 指令所需的功能单元忙
- Texture,Constant: 这两个缓存忙
- Instruction Fetch: 指令缓存缺失
- Memory Throttle: 有大量的存储访问操作未完成
- Memory Dependency: 由于请求资源不可用或满载导致访存单元无法执行
- Synchronzation: 等待同步指令
- Excution Dependency: 数据依赖
在一个指令解码完成之后,会被送入指令缓冲中,当线程束就绪后便可设置指令缓冲的就绪字段,调度器便从这些就绪的指令束中进行调度。
如果有多个就绪的指令束,便需要选择一个进行发射。早期使用轮询(Round-Robin RR)调度策略。也就是设置一个指针,然后每次从指针处开始遍历是否存在就绪的指令,如果存在则发射。另一种方式是贪心策略,每次选择一个线程束一直执行直到遇到缓存缺失为止。
线程束调度优化
在GPU架构中,访存仍然是影响性能的主要因素,而发掘数据局部性是改善访存延时的最有效手段之一。一般来讲内核函数往往存在两种局部性: 线程束内局部性和线程束间局部性。线程束内局部性指的是数据被一个线程访问后,不久之后还会被同一线程束的其他线程访问。线程束间局部性指的是线程访问数据后,还会被其他线程束的线程访问。
假设处理器内有多个线程束执行同样的指令,现在的指令为执行一段时间计算之后执行访存指令。如果使用轮询策略,那么所有线程束同步向前执行直到同步遇到访存缺失,那么将会有一段时间内所有线程束都在等待导致处理器空闲。
为了针对轮询调度针对长延时操作表现不佳的问题,文献[1]中设计了两级轮询调度策略。这种策略将线程束分成若干组,每次先只执行其中的一组,直到一组中所有线程束都执行访存指令时再切换到下一组。
此外,l1缓存的容量往往很小,对应到某个线程可能只能分到几个字节。如果大量线程同时进行访存势必会导致严重的冲突。一种方法是通过降低同时活跃的线程束数量来提高每个线程束可以获得的缓存容量,这种方法也称为限流(throttling)技术。文献[5]基于这个问题提出了缓存感知的调度策略(CCWS)。CCWS通过限制处理器中可以发射缓存指令的线程束数量,保证L1缓存中的数据得到充分利用。
CCWS的核心思想是:如果线程束发生缓存局部性缺失,则为他提供更多的缓存资源.具体的来说,它为每个线程束维护了一个受害者缓存,缓存中包含每次缓存缺失的信息。如果本次缓存缺失和受害者缓存中的某一项匹配,说明短时间内连续发生了两次缓存缺失,也就是局部性缺失。这时我们可以增大该线程束的评分,当进行访存指令时优先使这个线程束执行,而不允许评分低的线程束执行。此后如果不发生局部性缺失,则每个周期降低评分。
记分牌
为了提高SIMT运算单元的效率,GPU中一般采用顺序执行的方式,但是GPU中的指令仍然需要多个周期才可以完成,因此为了保证前后指令之间避免数据相关导致的冒险,GPU中使用记分牌机制处理相关性。
记分牌的简单设计如下:记分牌为每个寄存器分配1bit来记录寄存器空闲状态。如果指令正在执行且目的寄存器为R,则将对应位置1.如果后续指令用到了这个寄存器则不能发射。
这个设计虽然简单,但是存在两方面的问题:
- GPU中存在大量寄存器,即使只为每个寄存器分配1bit也会占用大量空间
- 所有线程束调度时都需要访问记分牌,因此需要大量的端口。例如有64个线程束,每个线程束最多4个操作数,因此总共需要256个端口
记分牌的优化
NVIDIA的专利中提出了一种新的记分牌实现方式。该记分牌是一个二维数组,每一行表示一个线程束,每一列表示一个正在占用的寄存器。每一项包含两个属性: 寄存器RID和尺寸指示器。寄存器RID表示当前未写回的寄存器编号,如果有多个连续的未写回数据则表示开头的寄存器编号。而尺寸寄存器表示了该寄存器序列的长度。
每次进行检查时,取出记分牌中对应的行,将源寄存器和该行中每一项进行比较,如果有冲突则存在依赖。每次发射出去后,会分配新的一项并且将目的寄存器编号存入其中。