gpu存储架构
本文最后更新于 2023年9月12日 晚上
本篇是《通用图形处理器设计-GPGPU编程模型与架构原理》的阅读笔记
gpu存储结构简介
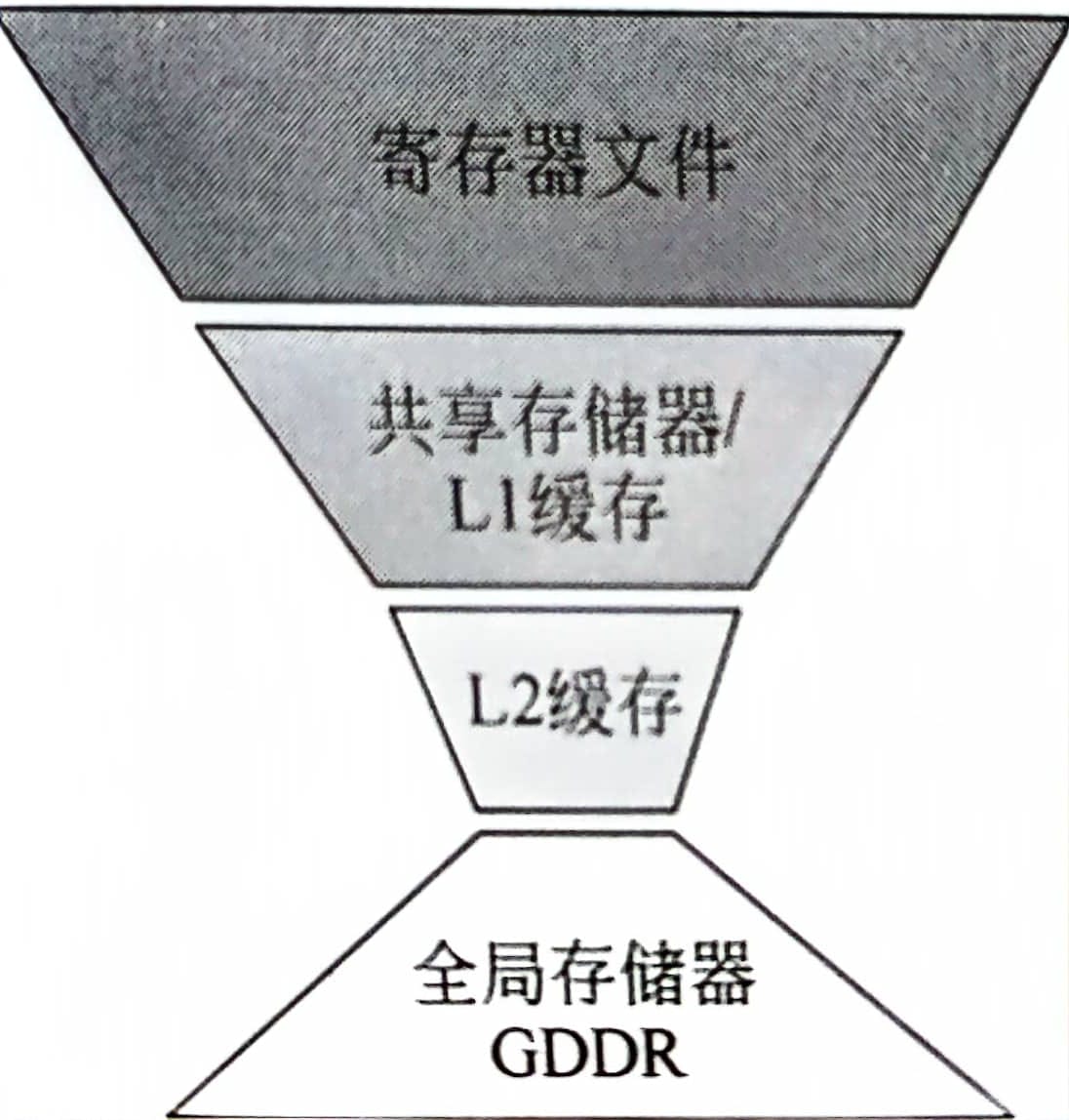
gpu存储和cpu截然不同,呈现倒三角的结构。gpu使用如此多的寄存器文件主要是为了线程束的零开销切换。因为每个线程束都有它自己的寄存器,因此每次切换线程束时就不需要像cpu线程切换时那样将寄存器存入内存再读取了。
大容量寄存器带来的一个负面影响是L1和L2缓存的容量被大量挤压,在Pascal架构中超过60%的片上存储容量被分配给了寄存器。在NVIDIA V100架构中每个核最多128kb的l1数据缓存容量,而每个核中最多有2048个线程,也就是说每个线程只能分配到64b的空间。而l2缓存的容量有6mb,远小于l1数据缓存共10mb的容量。
寄存器
gpu处理器的高并行导致每个核需要大量的寄存器端口。例如如果同时执行32个线程,每次需要读取3个操作数,那么要求寄存器文件每周期需要提供96个32bit的读端口和32个写端口。而寄存器在存储中占了绝大部分比重,大量的资源消耗导致寄存器无法使用激进的多端口设计。gpu中往往使用多bank的单端口来模拟多端口的设计。
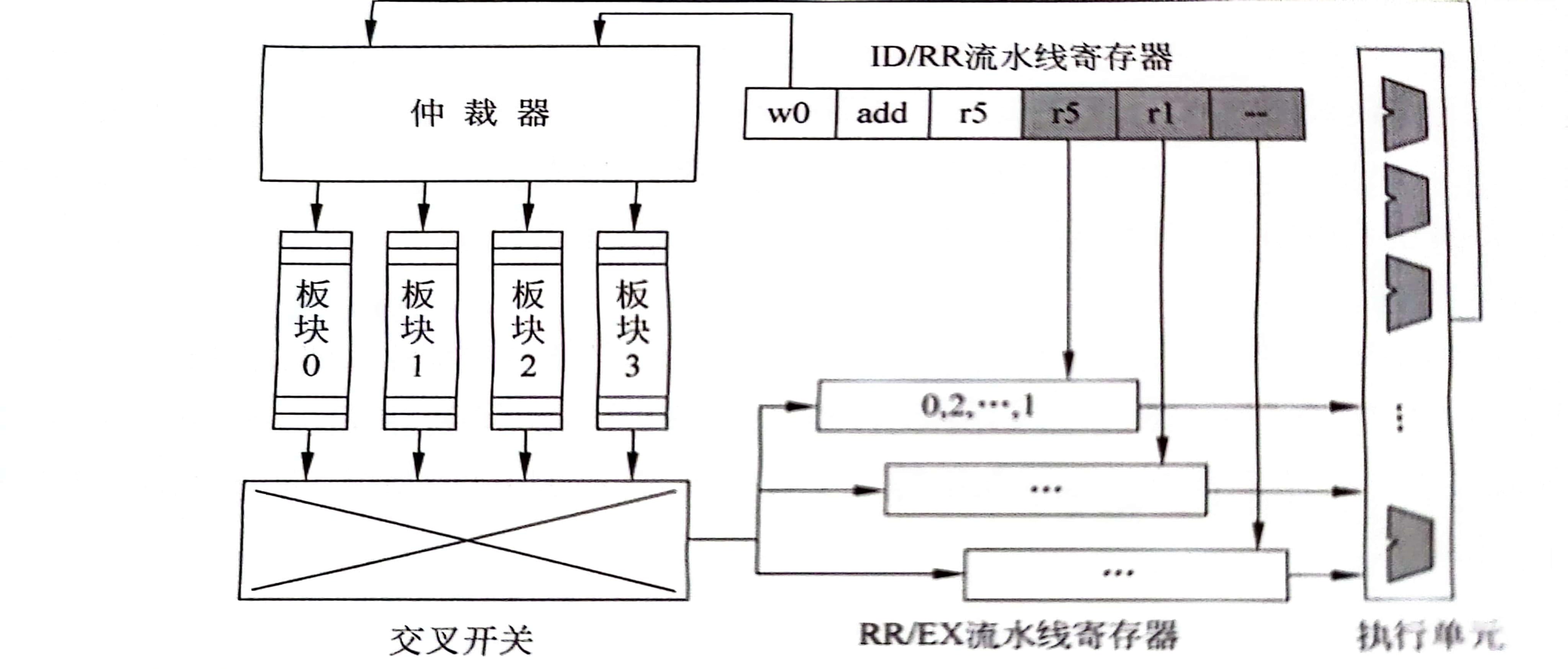
如图所示为多板块寄存器的设计结构。在读寄存器阶段,仲裁器会根据线程束id和寄存器编号确定读取的板块和读取的位置,在读取完成之后通过交叉开关送入指定的执行单元,然后再将结果写回寄存器。
那寄存器在板块之间是如何排布的呢?首先获取寄存器的位置需要的两个值中,线程束id和寄存器id是确定的,在NVIDIA中,同一线程束中线程id是顺序递增的,因此可以将一个线程束中所有寄存器打包成一个大的寄存器,而每两个线程束之间的寄存器顺序排放即可,一种排布方式如下图所示。
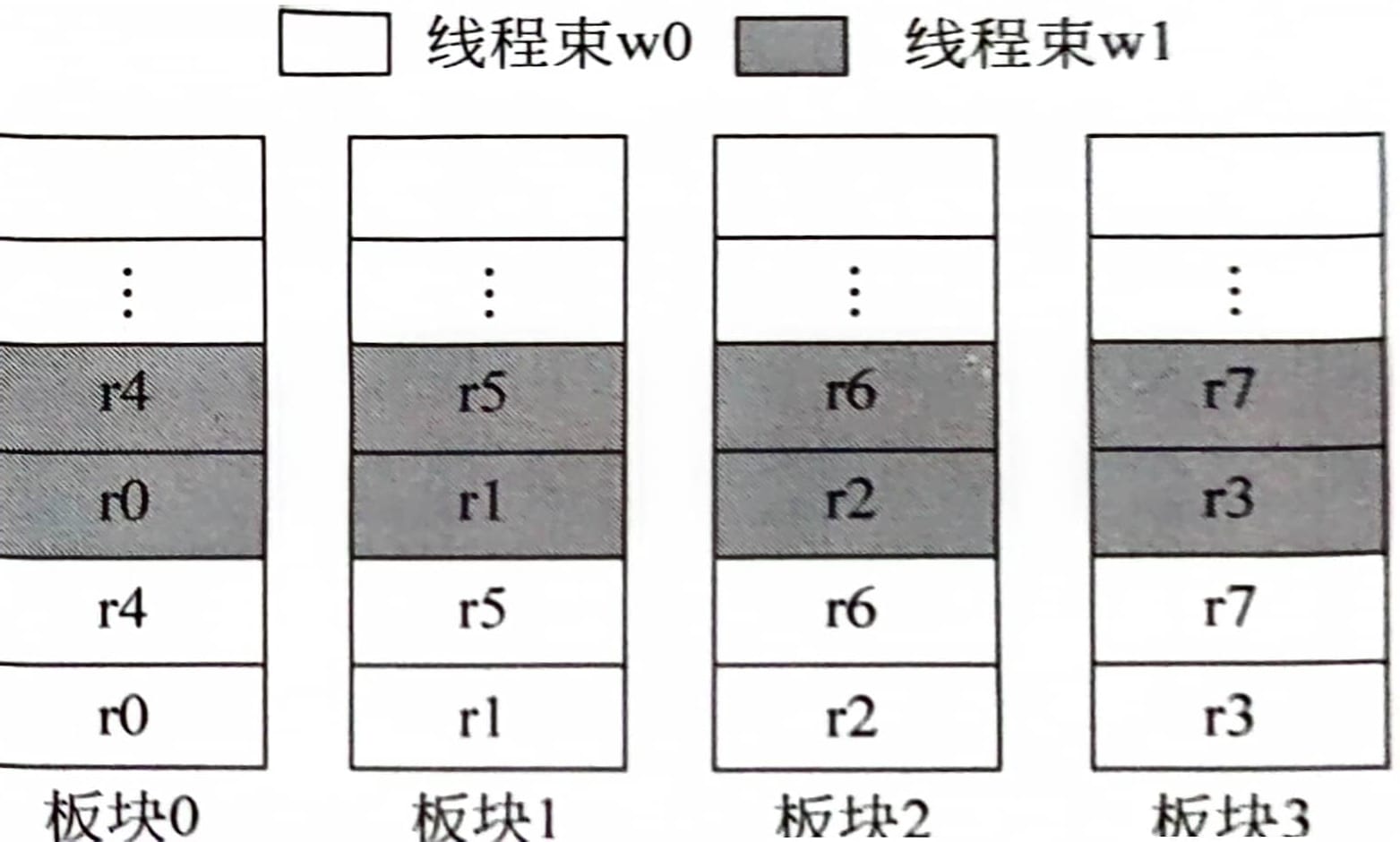
可以看到图中的板块数量是要比逻辑寄存器的数量少的,也就是说同一指令的两个寄存器可能映射到同一板块。例如add x5, r5, r1,其中r5和r1是在同一板块的,因此必须要等待一周期才可以完成寄存器的读取。
针对板块冲突导致寄存器文件访问效率低的问题,可以通过收集尽可能多的指令同时访问操作数,尽可能多大利用板块来提高访问效率。基于这个思路,提出了操作数收集器的概念。也就是操作数取出来之后加一个缓冲,先将操作数存入缓冲之中,待所有操作数都取出来了再送给执行单元。这样通过同时缓存多条指令,就可以提高板块的利用率。
线程束调度也可能会导致板块冲突,如前文中提到的线程束调度的基本策略是轮询,也就是说调度器会尽量选择相同pc的指令发射。这时线程束之间只有id不同,但是寄存器编号相同,这样两个线程束同时访问寄存器便会导致严重的冲突。
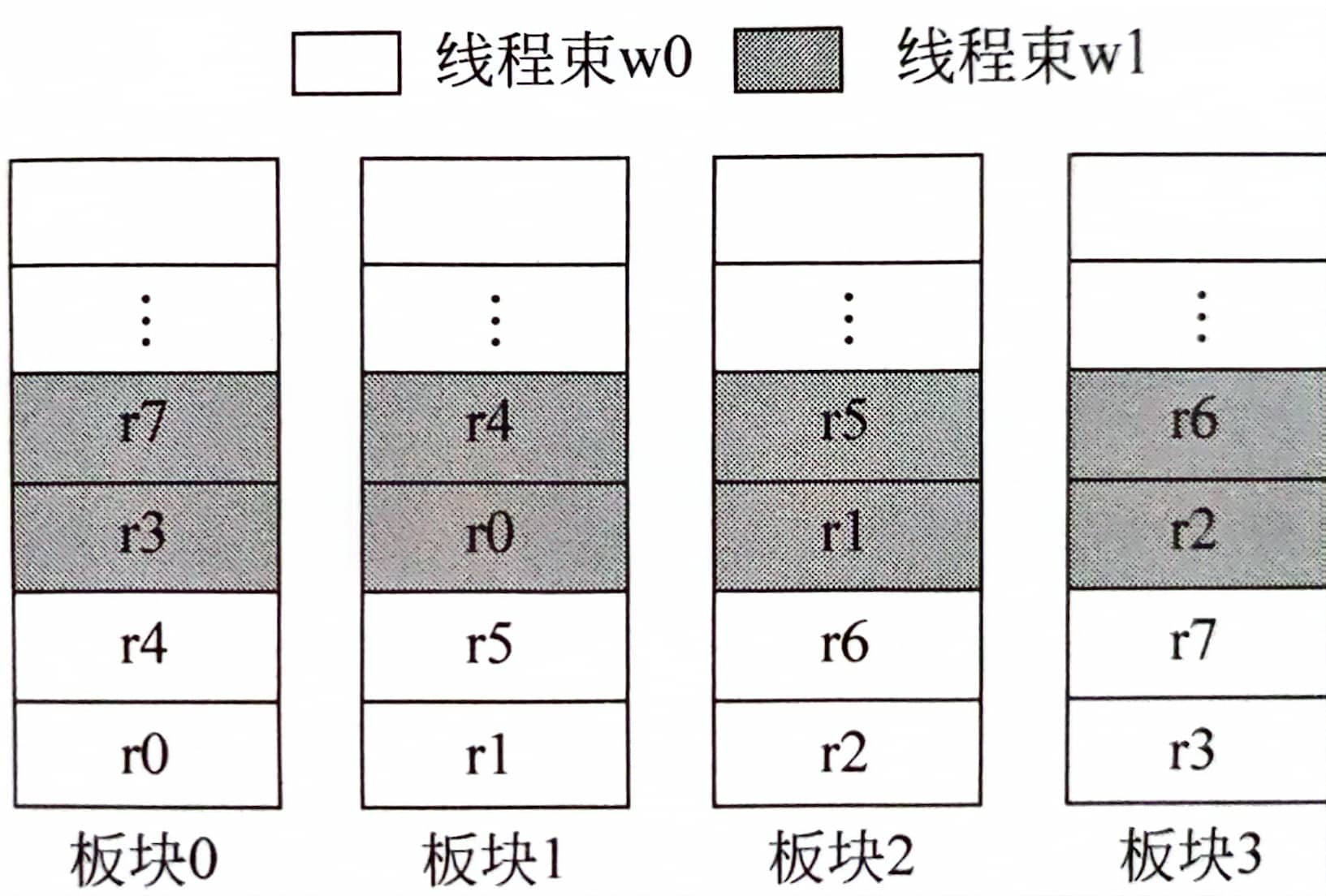
改进方法为寄存器在板块间交错分布。如下图所示
并行访问时的冒险
由于使用了操作数收集器,多条指令可以同时访问寄存器,因此可能导致后面的指令先读取完导致相关性冒险。例如现在操作数收集器中有两条指令,后面一条要写入的寄存器是前面一条读取的寄存器。如果前面一条指令产生冲突导致后面一条指令先读取完成,这样当前面一条指令读取操作数便是后面一条指令的结果了。
这个问题有多重解决方法。第一种方法是每个线程束每次最多执行一条指令。另一种方法是要求每个线程束每次只能有一条指令在操作数收集器中,这样对性能的影响较小。
寄存器的优化设计
增加前置寄存器文件缓存
大容量的寄存器文件带来了较高的寄存器访问功耗。通过对多个程序进行测试发现,高达40%的寄存器数据只会被读取一次,而且这些数据往往会被而后产生的三条指令读取。这些数据存入寄存器堆然后再读取便会产生大量的功耗。
文献[1]中提出了小容量的寄存器缓存(RFC)来捕捉这些短生命周期的数据。它的工作原理为:每次写回数据时先写到RFC中,然后读取也先从RFC中读取,如果未命中再从MRF中读取。如果完成了最后一次读取的寄存器将被标记为死寄存器,在发生替换时无需写入MRF中。
此外还设计了一个两级调度器,将线程分成活跃线程和挂起线程,只有活跃线程才可以拥有RFC,如果一个活跃线程遇到长延时操作,那么切换到挂起线程,并且清除其在RFC中分配的条目,然后从挂起线程中挑出一个准备好的,使其变为活跃线程。
使用eDRAM代替sram
sram需要使用6个晶体管,大容量的sram使得面积和能耗成为瓶颈。因此提出使用嵌入式动态随机访问存储器(embedded-DRAM eDRAM)来代替sram。eDRAM只需要4个晶体管,但是eDRAM的频率要低一些。由于GPU的工作频率一般只有1GHz左右,因此eDRAM的速率基本满足要求。
eDRAM还有一个重大缺陷是他也像DRAM一样需要刷新操作。为了隐藏刷新时间,可以利用寄存器中多板块并行的特性。例如一条指令两个源操作数均位于同一板块中,这样便会造成指令停顿,这一时期其他的板块可能是空闲的,为刷新提供了时机
数据压缩的寄存器设计
由于一个线程束中的线程数据往往具有相似性,因此可以利用这种相似性进行数据压缩。一种实现方法(BDI)的操作方式为: 每次使用其中一个线程的寄存器作为基值,计算其他线程和该线程的差值,如果差值过大则不进行压缩。最后使用一个标志位表示当前寄存器是否被压缩
存储系统
访存单元
L1存储器也是使用多板块SRAM的设计,如果有32个板块,那么一周期最多取出32个数据。如果没有冲突,那么每个板块会对传过来的地址进行译码,然后通过交叉开关送给指定线程的寄存器。
如果有冲突,仲裁器会对请求进行拆分,经过拆分,会形成互相没有冲突的多个子集,然后通过多周期访问获取数据。另一种方式是将冲突的请求退回流水线要求重新发射。
l1缓存
l1缓存的访问模式和cpu中差别不大,注意l1这一层次有三个缓存,分别是数据缓存,常量缓存和纹理缓存。其中常量缓存和纹理缓存都是只读的
优化设计
gpuL1缓存资源紧缺,导致冲突问题时有发生。文献[2]中提出了使用缓存旁路的方式管理缓存。这一技术在CPU中也存在,但是由于CPU中L1缓存命中率较高,因此只对最后一级缓存进行旁路。它的基本思想是部分请求选择绕过L1缓存,返回的数据也将直接发送给寄存器。另外较高的缺失率还会导致MSHR拥塞而带来的流水线停顿,通过将一些请求直接发送给L2缓存,也有助于减少资源拥塞。
- Gebhart, Mark, et al. Energy-efficient mechanisms for managing thread context in throughput processors. Proceedings of the 38th annual international symposium on Computer architecture. 2011. ↩
- Xie, Xiaolong, et al. Coordinated static and dynamic cache bypassing for GPUs. 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2015. ↩