向量处理器和gpu
本文最后更新于 2023年10月30日 下午
向量处理器
传统的处理器每一条指令只能针对一个数据执行加减乘除等操作,而向量指令可以在一条指令中实现对多个数据进行操作。
RV64V的主要构成为:
- 向量寄存器:供32项,每一项包含32个64位元素。向量寄存器至少有16个读端口和8个写端口。为了实现大带宽,通常做法为使用多个存储体来组成寄存器堆
- 向量功能单元: 包括加减乘除,逻辑运算,浮点运算等单元,所有单元都是完全流水化的
- 向量存储/载入单元: 可以复用标量存储单元,然后每个周期取1-2个数据
例如给出下面一段代码,并使用向量指令实现
1 | |
使用RV64V实现为1
2
3
4
5
6
7
8vsetdcfg 4*FP64 # 启用4个双精度浮点向量寄存器
fld f0.a # 载入标量a
vld v0.x5 # 载入向量X
vmul v1.v0.f0 # 向量-标量乘
vld v2.x6 # 载入向量Y
vadd v3.v1.v2 # 向量-向量加
vst v3.x6 # 禁用向量寄存器
vdisable
在标量处理器中,每次执行add都需要等待mul,但是在向量处理器中,mul执行完成之后才会执行add,因而没有等待,这类似于循环展开。
执行时间
一些术语:
- 通道: 即功能单元。例如执行vadd,并且由4个加法功能单元,则称有4个通道
- 护航指令组: 可以一起执行的一组指令,这些指令之间不存在结构冒险。例如vld和vmul就是一组护航指令组
- 钟鸣: 用来估计护航指令组的长度,有三个护航指令组便有3个钟鸣
执行一个护航指令组的时间包括启动时间和一次钟鸣所需要的时间。
启动时间即填满流水线所需要的时间,不同的处理器所需时间不同。浮点加为6周期,浮点乘为7周期,浮点除为20周期,向量载入12周期。
钟鸣所需时间由向量长度n和通道数m决定,所需时间为n/m
控制寄存器
向量长度寄存器
向量寄存器有一个最大的向量长度,它受限于寄存器的大小,在本例中长度为32。但是不可能将所有向量指令长度都变为32。因此需要动态调节向量指令的长度,解决方法是添加一个向量长度寄存器
谓词寄存器
谓词寄存器是为了从转山循环中的条件语句
例如下列循环1
2
3
4for(int i=0; i<64; i++){
if(x[i] != 0)
x[i] = x[i] - y[i];
}
通常情况这种循环无法向量化,但是如果我们只执行x[i] != 0的循环体,那么便可以实现向量化。
这一功能通常使用谓词寄存器实现,谓词寄存器中保存了向量的掩码,只有掩码为1对应项才会存入寄存器中
步幅
前面的向量指令都是处理相邻的数据,即步长为1,但是在多维数组中数据往往不相邻,例如
1 | |
可以看到,d取出的相邻两个元素之间中间还有100个元素,即步幅100.这时我们需要使用vlds(load vector with stride)和vsts(store vector with stride)存取数据
在一些科学计算中,稀疏矩阵很常见,他们往往使用压缩的方式进行存储。例如
1 | |
稀疏矩阵的主要机制是采用索引向量的集中-分散操作。集中即集中获得索引向量,然后根据索引向量获得元素,分散即根据索引向量分散存储
GPU
GPU编程
为了协调cpu核gpu之间的调度,nvidia设计了一种和c类似的编程环境,称为CUDA(Compute Unified Device Architecture, 统一计算设备体系结构)。
NVIDIA认为所有并行的统一主体是CUDA线程。然后将这些线程划分成块,分组执行,称为线程块。执行线程块的硬件称为多线程SIMD处理器
CUDA中的一些定义:
- 为了区分GPU和CPU,CUDA使用device或global代表GPU,使用host代表CPU
- 使用device申明的变量被分配给GPU存储器,可以供所有的SIMD处理器访问
- 函数的扩展语法为其中dimGrid和dimBlock指定了块的数量和块的大小
1
name <<<dimGrid, dimBlock>>>(args..) - blockIdx用来表示当前是第几个块,threadIdx表示当前是块中的第几个线程,blockDim表示前面的dimGrid参数
例如:1
2
3
4
5void daxpy(int n, double a, double* x, double* y){
for(int i=0; i<n ; i++){
y[i] = a*x[i] + y[i];
}
}
使用CUDA表示为1
2
3
4
5
6
7
8
9__host
int nblocks = (n + 255) / 256;
daxpy<<<nblocks, 256>>>(n, 2, x, y);
__global__
void daxpy(int n, doublea, double* x, double* y){
int i = blockIdx.x * blockDim.x + threadIdx.x; // 第blockIdx个线程块中第threadIdx个线程
if(i < n) y[i] = a * x[i] + y[i];
}
GPU结构
由于GPU和CPU的一些术语有差异,阻挡了我们理解,因此首先对一些GPU名词进行解释
| GPU术语 | 描述性名称 | 解释 |
|---|---|---|
| 网格 | 可向量化循环 | 指可以送入GPU中进行计算的循环,由若干线程块组成 |
| 线程块 | 可向量化循环体 | 将送入SIMD处理器的一组指令 |
| CUDA线程 | SIMD单通道上的操作序列 | 即一个可执行单元上执行的一次操作,CUDA中最小的执行单元 |
| PTX指令 | SIMD指令 | 一条向量指令,在多个通道中执行 |
| 流式多处理器 | 多线程SIMD处理器 | 用于执行SIMD指令的处理器,和前面提到的向量处理器类似 |
| 亿数量级线程引擎 | 线程块调度器 | 将线程块分配给多线程SIMD处理器 |
| Warp调度器 | SIMD线程调度器 | 将向量指令中准备好的部分分配给通道执行, 也就是将SIMD线程分配给线程处理器执行 |
| 线程处理器 | SIMD通道 | 执行加减乘除的操作单元 |
| 全局存储器 | GPU存储器 | 供所有处理器访问的DRAM处理器 |
| 局部存储器 | 专用存储器 | 单个SIMD通道所使用的DRAM存储器部分 |
| 共享存储器 | 局部存储器 | 一个多线程SIMD处理器可以访问的SRAM,类似于Cache |
| 线程处理器寄存器 | SIMD通道寄存器 | 也就是向量寄存器中的一项 |
例如:
1 | |
网格就是在GPU上运行的,由一组线程块构成的代码,资产本例中就代指这个循环。而dimGrid表示线程块的数量,也就是说每个线程块中包含8192/16=512个乘法,然后这些乘法每32个当做一组向量送入多线程SIMD处理器中。
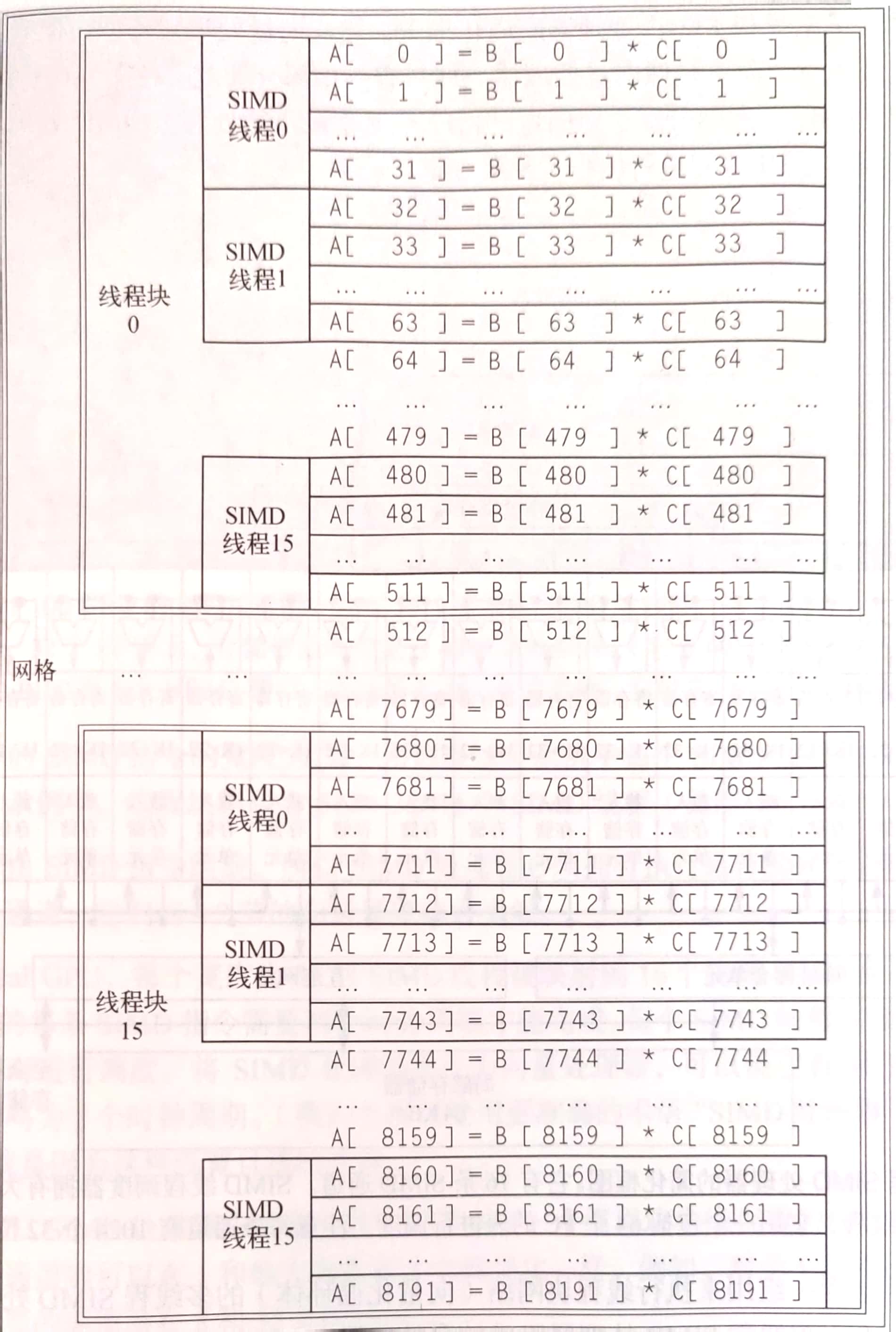
如图所示为划分好的结构,其中SIMD线程可以看做向量。线程块调度器将线程块分配给某个多线程SIMD处理器。然后SIMD线程调度器将准备好的线程送入执行单元进行执行。
一个GPU可以有一到几十个多线程SIMD处理器。而一个处理器可能有若干SIMD通道(也就是执行单元)。例如一个处理器有16个通道,本例中一个向量大小为32,那么需要执行两个周期才可以执行完一条向量指令,也可以称钟鸣为2个周期。
NVIDIA GPU指令集
NVIDIA提供了一系列指令用于编程,他们统称为PTX指令
PTX指令的格式为:opcode.type d a b c;
其中d是目标操作数,abc是源操作数。type可以是无符号,有符号或浮点的8,16,32,64位数,可以记作[b|u|s|f][8|16|32|64]。如b8, u16等
GPU中的条件分支
例如:
1 | |
使用PTX指令实现为:
1 | |
其中bra为分支指令,主要P1为假或为真需要P1中的每一个元素都为假或为真,否则还是顺序执行。也就是说IF-THEN-ELSE语句中的所有指令通常都会被SIMD处理器执行。
GPU存储器结构
本节将从大到小介绍各级存储器。
最大的是GPU存储器,它是供整个网格使用,上面例子中的函数便存储在这一级的存储中。
其次为局部存储器。它是一种很小的存储器,延迟低(几十周期),带宽高(128bit/每周期)。他可以被同一线程块中所有线程共享,但是不能被用于同一SIMD处理器上不同线程块使用。SIMD处理器创建线程块时,会动态分配给该线程块。
最后是专用存储器。这部分被每条SIMD通道专用,用于堆栈,溢出寄存器和寄存器中放不下的私有片段。他是从GPU存储器中的专用部分分出一块来给通道使用的。