tage分支预测器
本文最后更新于 2023年9月1日 晚上
介绍
tage分支预测器是现代高性能处理器中常用的预测器,他使用pc和全局历史作为输入,通过哈希得到index和tag进行查表,并且谨慎的只更新少数表来减少表项的占用。在一些测试集中可以达到95%以上的准确率且低于5MKPI
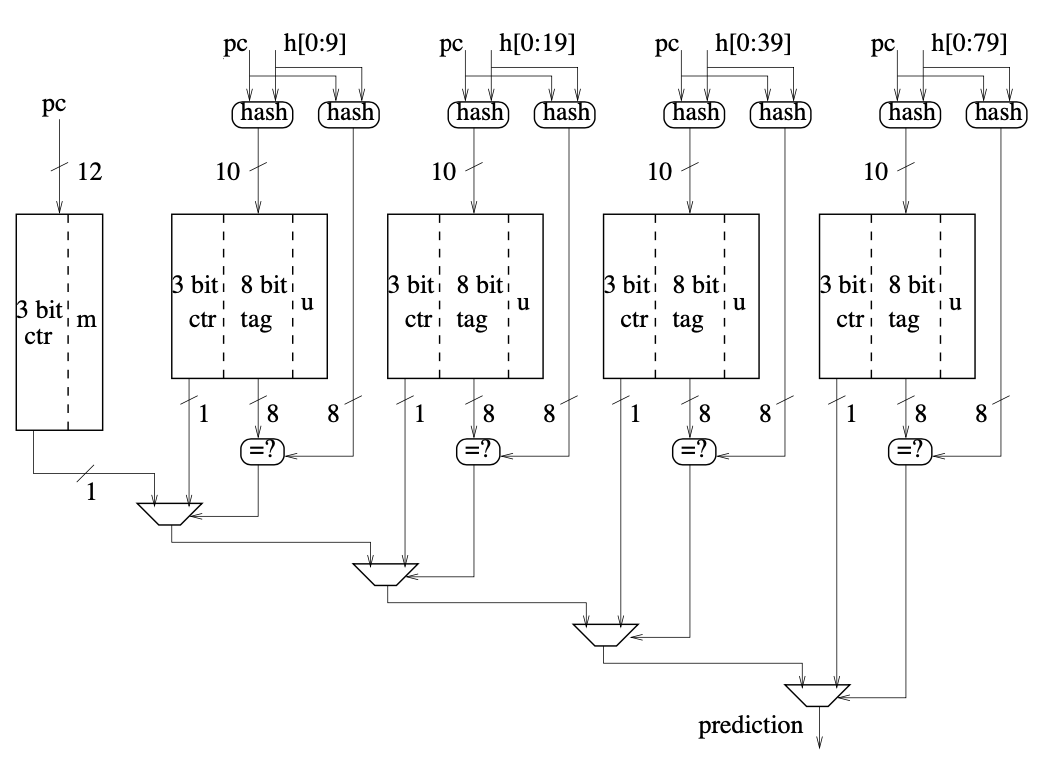
预测
tage分支预测器由一个base表和多个tage表组成。
base表是一个类gshare预测器,使用pc的哈希作为index。
tage表由三个部分组成,tag,u和ctr。其中ctr为饱和计数器。使用pc和不同长度的全局历史查表
tage表的查表方式为将pc和n位的全局历史使用不同的哈希函数分别获得index和tag,然后使用index获得表中的某一项表项,再使用tag进行匹配表项中的tag,如果匹配成功则使用表项中的饱和计数器作为最终结果。
如果有多个表成功匹配,则将最长历史的表的结果作为最终结果,如果全部没有匹配,则使用基础预测器作为最终结果
在实现时,如果历史长度较短,则可以直接将历史异或,进行折叠来获得index和tag。如果历史长度较长,则可以选择历史中的某几位和上一步计算结果进行逻辑操作来生成index和tag。
更新
更新是tage分支预测器能取得优良效果的重要原因。
一些定义:
- 候选者(provider): 该预测结果所使用的表
- 备用候选者(alt provider): 排除候选者将使用的表
更新阶段需要更新tag,u和ctr或分配新的表项:
- ctr: 如果预测成功,则只需要更新候选者的ctr,否则初始化新的表项
- tag: 当初始化新表项时更新
- u: 如果分支预测成功,并且alt provider和provider的预测结果和provider的预测结果不同,则增加u。如果分支预测失败,则需要根据u选择一个表来分配新的表项。选择方式为: 在当前表之后的表中挑选出u=0的表,第i+1个表被选中的概率为第i个表的1/2。如果所有表都被选择,那么将所有表的u都降低。最后每隔若干周期需要降低所有表的u,来避免表项占用。
tage分支预测器
https://www.xinhecuican.tech/post/bd974a32.html