Hadoop和Spark
本文最后更新于 2021年6月22日 上午
Mapreduce
mapreduce是一种编程模型,它的基本思想就是分而治之。
map()负责将一个任务分解成若干个小的任务,这些小的任务可以交给不同的计算节点去处理,Reduce()负责把这些计算结果进行合并。
例如统计词频:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20a a a
aa
aaa
bc
de
bc
abc
abc
想要统计这些次出现的次数
首先进行map,例如有4个工作节点,我们可以把每两行给一个工作节点,然后这些工作节点就会进行词频统计,最后得到
('a', 3), ('aa', 1)
('aaa', 1), ('bc', 1)
('de', 1), ('bc', 1)
('abc', 2)
之后把这些计算结果发给主节点,然后主节点进行reduce, 也就是把各个工作节点产生的结果组合到一起。
('a', 3), ('aa', 1), ('aaa', 1), ('bc', 2), ('de', 1), ('abc', 2)
map和reduce都可以并行化执行,也就是说map结果可以发给多个节点,然后多个节点每个处理部分工作。
hadoop
hadoop是mapreduce思想的具体实现,它有自己专门的文件管理系统和任务分配系统。
分布式文件系统(HDFS)
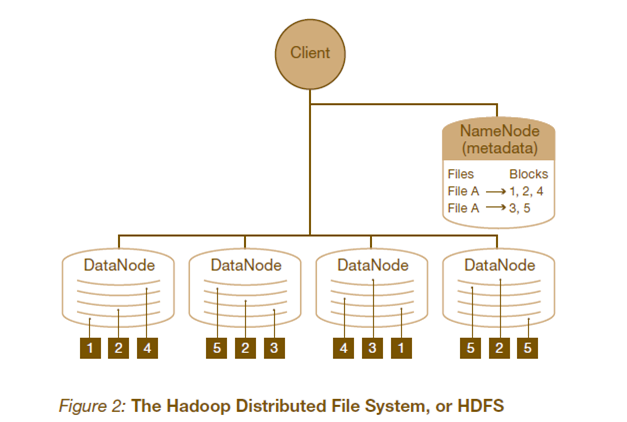
- block: hdfs中数据存储的基本单位事一个block,一般来说block的大小是64mb。块大小这么大的好处有: (1) 减少磁盘寻道时间,增加读取效率 (2)减少namenode存储开销 (3) 减少建立网络的连接成本。 但是如果里面全是小文件的话,会造成大量的空间浪费
- NameNode: namenode是数据的管理者,它存储着文件的metadata[1]。一个block对应着namenode中的一条记录。并且他会不定时的存储到本地磁盘上,但不保存metadata的位置信息,而是由datanode上传这些信息
- datanode: 具体存储block数据。它负责数据的读写操作。datanode会定时发送心跳报告存储的数据块信息
- client: 需要获取文件的应用程序
写入文件过程:
- client向namenode发起文件写入请求
- namenode创建一个文件,并且把blockid和要写入的datanode列表发给client
- client接收到信息后,会把文件写入datanodes
- 客户端写入第一个datanodes
- 第一个datanodes写入第二个datanodes,以此类推。每次写入都会发送确认给前一个datanode,最后第一个datanode发送给客户端确认信息
- 客户端给namenode发送确认信息
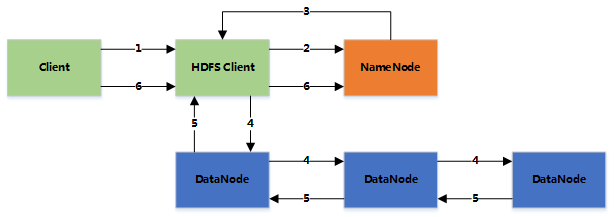
读取文件过程:
- 客户端向namenode发送请求
- namenode返回该文件的所有block和block所在的datanodes
- 客户端直接读取
hdfs还有一些安全策略,如检验和,副本(一般是三个副本),心跳检测,机架感知等等
资源管理系统(yarn)
旧有的资源管理系统
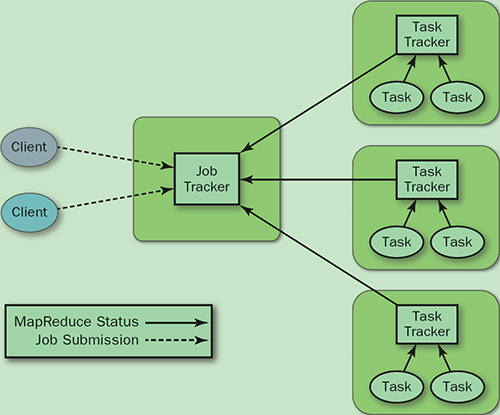
- Jobtracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- tasktracker: 加载或关闭任务,报告任务状态
但是他有一些问题:
- Jobtracker存在单点故障,如果它出问题整个系统都不能运行
- jobtracker完成了太多任务
- tasktracker将任务强制划分成了map slot和reduce slot。如果系统中只有map或reduce就会带来资源的浪费
yarn针对这些问题做出了一些改进,他将jobtracker的职责进行了拆分,分成了资源管理和任务调度两个部分。
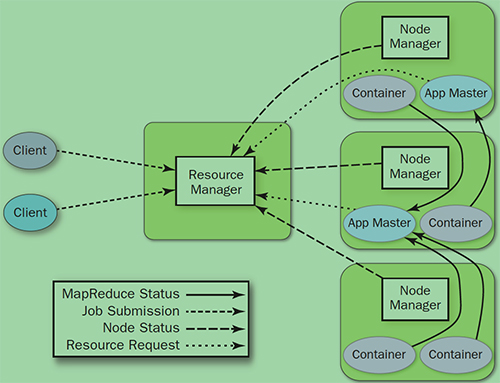
- ResourceManager: 全局资源调度
- NodeNamager: 单个节点的资源管理
- ApplicationManager: 单个作业管理。主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个 Map task 和相应的 reduce task Application Master 还决定如何运行作业,如果作业很小(可配置),则直接在同一个 JVM 下运行
- container: 资源申请的单位和任务运行的容器
具体步骤
- Job submission: 从ResourceManager中获得一个Application ID来检测作业输出配置,计算输入分片,拷贝作业资源(job jar, 配置文件, 分片信息)到HDFS, 以便后面任务的执行
- Job initialization: ResourceManager把作业递交给schedule并且schedule分配一个container, 然后ResourceManager加载一个ApplicationManager并且给nodeManager
- taskAssignment: ApplicationManager向Resource Manager申请资源
- task execution: ApplicationMaster 根据 ResourceManager 的分配情况,在对应的 NodeManager 中启动 Container 从 HDFS 中读取任务所需资源(job jar,配置文件等),然后执行该任务
- 定时将任务的进度和状态报告给 ApplicationMaster Client 定时向 ApplicationMaster 获取整个任务的进度和状态。client也会定时检测整个作业是否完成,会清空临时文件,目录等。
mapreduce
大致流程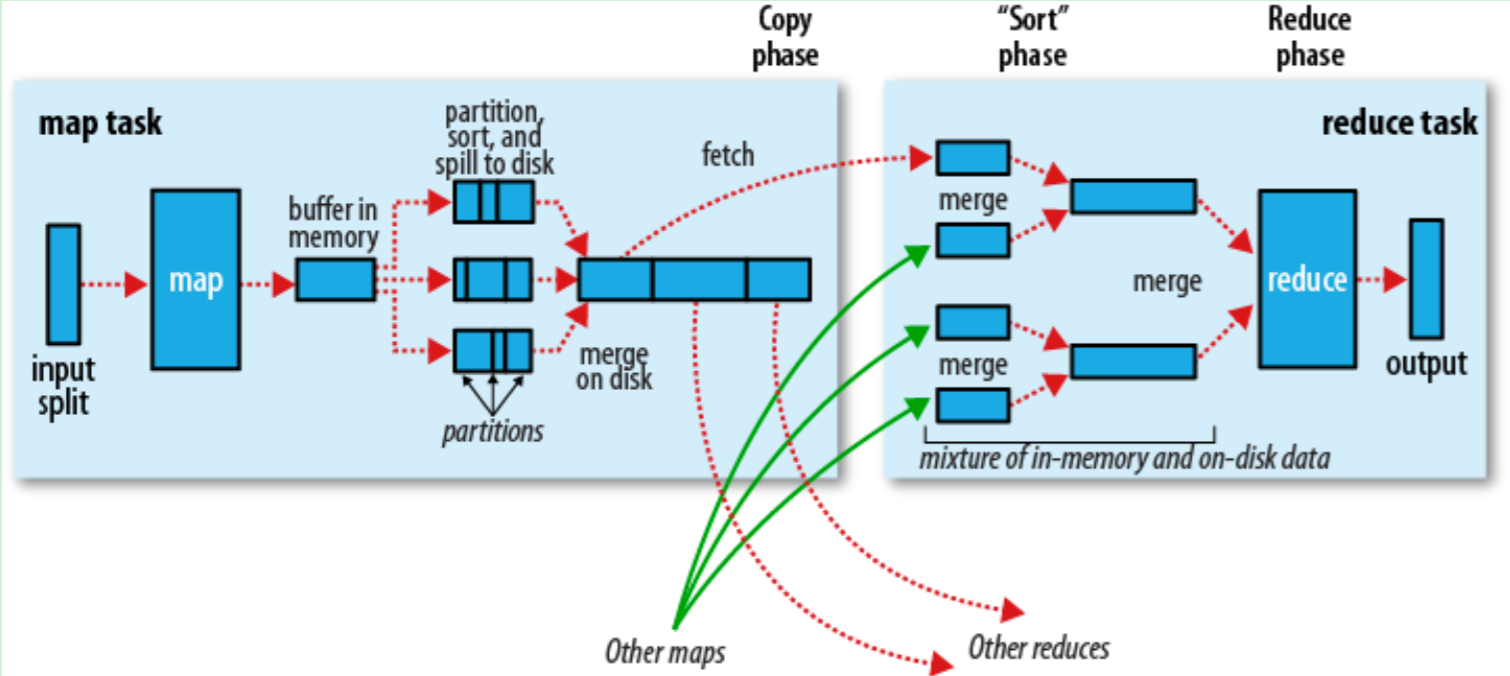
首先通过inputformat决定数据类型,然后拆分成一个个inputsplit,每一个inpusplit交给一个map执行,RecoderReader读取inputsplit提交给map
inputformat
功能:
- 验证文件的正确性
- 将输入文件进行逻辑分片
- 提供RecoderReader的实现,读取inputsplit提交给mapper
一般是每一行代表一个记录
inputsplit
inputsplit并没有真正分片,只是提供了分片的方法,也就是location和length
map
当RecoderReader真正将文件分片并且提交到每一个mapper后,mapper开始工作。
每一个mapper都有循环内存缓冲区(默认100mb),当缓存内容达到80%后,后台线程开始百内容写到文件,同时mapper还可以使用剩下20%的内存。
每次写文件时都是产生一个新的文件进行写入,并且在写入文件前还会按照reduce的要求进行分区和排序,之后在map结束之后会把这些文件进行合并。合并完成之后reduce就可以来拷贝数据了。
reduce
reduce的输入数据就是map的输出数据,这些数据是分布在集群中的,所以只要有任务完成,reduce就会把数据进行拷贝,默认拷贝线程为5.
当所有map的数据都获得之后,就会开始归并,这个阶段可能要进行多次。例如每次把十个文件归并成1个,如果总共50个文件,那么第一次归并成5个文件,但是第二次就不会再归并了,直接提交给reduce函数。
spark
hadoopmap中间结果需要存入硬盘,即使使用了循环内存缓冲区,但是速度还是很慢。而spark中间结果存储在内存中,并且采用了先进的架构,因此它的速度比hadoop快十倍到百倍不等。
spark支持python和java两种语言,并且它实际上是hadoop的补充,因此也可以用在hadoop上
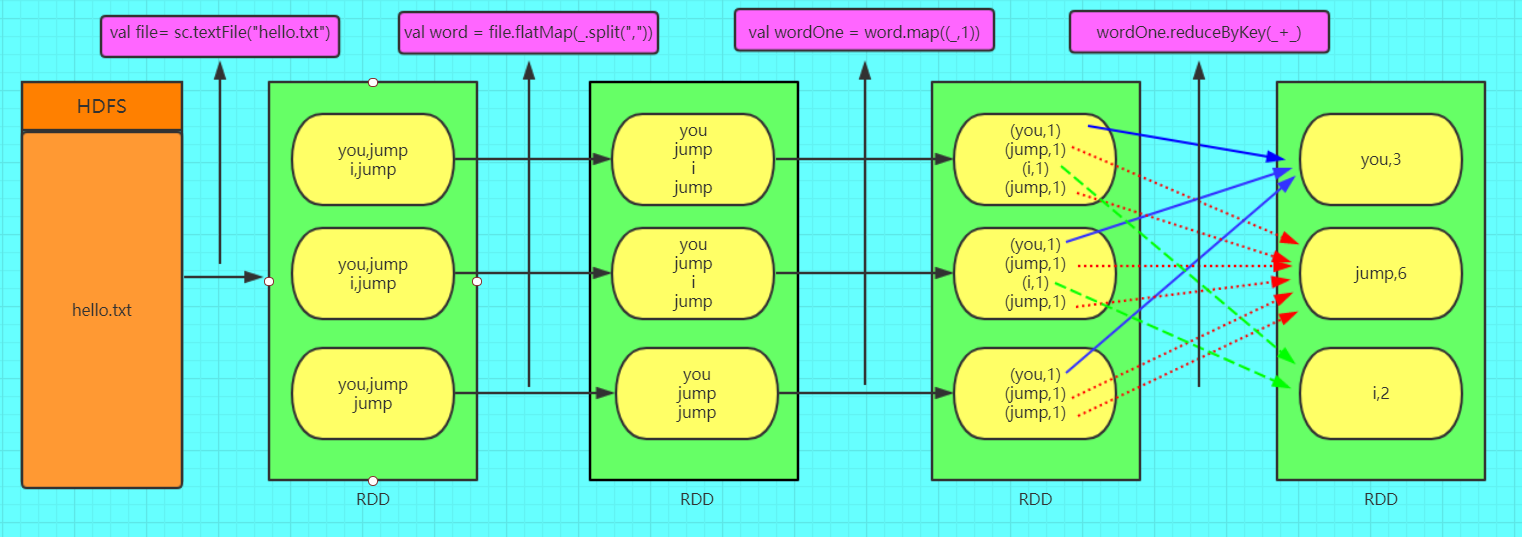
RDD
RDD叫弹性分布式数据集,是spark中对数据的抽象,这些数据可以全部或者部分缓存在内存中,在多次计算之间重复利用。
RDD属性:
- 分片(Partition): 是数据集的基本单位。每一个分片都会当做一个计算任务处理。用户可以在创建RDD时指定分片数目。如果没有指定,其数目为程序所分配的cpu数目。
- 计算函数: 每个分片都会运行这个函数
- 依赖关系: RDD每次转换都会产生新的RDD,在分区数据丢失时,RDD通过这个依赖关系恢复数据。
- 分片函数: 只有(key, value)类型的才会有分片函数。分片函数可以是哈希也可以是一个range
创建
1 | |
RDD持久化
如果一个rdd被多次使用,则需要考虑持久化
持久化之后,下次查询rdd时,就可以被快速访问,不需要计算
可以使用persist或cache方法进行持久化
RDD的操作
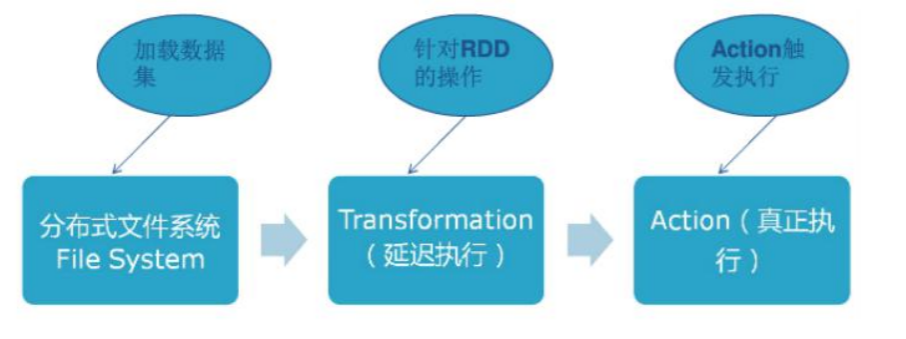
RDD的任何transform都是惰性的,也就是说transform时并不会真正执行,只有运行action后才会真正执行。
transform
transform作用在一个RDD上,产生一个新的RDD
- map(func): 返回一个新的rdd,新的rdd中每一个元素都由func转化得来
- filter(func): 新rdd中元素由func计算得true而来
- mapPartitions(func): 类似于map,但是独立的在每一个分片上进行
- mapPartitionsWithIndex(func)
- sample(withReplacement, fraction, seed): 按照fraction比例进行采样,可以指定是否使用随机数进行替换,seed是随机数种子
- union(otherDataset): 合并
- intersection(otherDataset): 交集
- distinct([numtasks]): 补集
- groupByKey([numtasks]): 在一个(K, V)的RDD上调用,返回一个(K,Iterator(V))的RDD
- sortByKey([ascending], [numtasks]): ascending是排序方式,
- sortBy(func, [ascending], [numtasks]):
- join(otherDataset, [numtasks]): 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集)
- pipe(command, [envVars]): 调用外部程序
- reparation(num): 重新分区,num是分区数量
Action
- reduce(func): 通过func
- collect(): 以数组形式返回所有元素
- count(): 返回元素个数
- first(): 返回第一个元素
- take(n): 返回前n个元素
- takesample(): 和上面一样
- saveAsTextFile(filepath):
- countByKey(): 返回一个(K, int)类型的map
- foreach(func): 在数据集每一个元素上,运行func进行更新
- reduce(func): 并行整理RDD中的每个元素,例如RDD中元素为(1, 2, 3, 3),则
rdd.reduce((x, y) => x + y);结果为9
spark执行过程
spark的执行可以看成一个DAG(有向无环图)
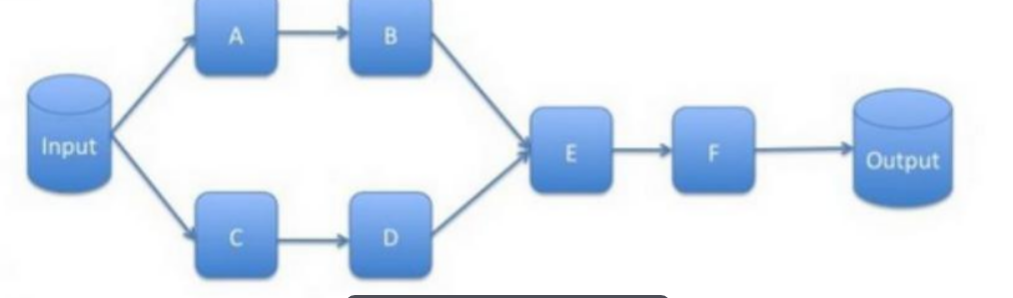
我们可以把这些RDD之间的依赖关系分为两种,宽依赖和窄依赖
- 窄依赖: 一个父RDD最多被一个子RDD调用,例如map,fliter,union等
- 宽依赖: 指子RDD分区依赖于父RDD的所有分区。例如grouByKey, reduceByKey, sort等
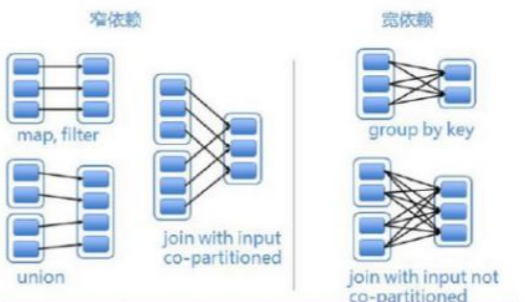
根据依赖关系的不同,spark将一个job分解成不同的stage,stage之间的依赖关系就形成了DAG图。
一般遇到了宽依赖就划分一个新的stage