本文最后更新于 2022年11月16日 晚上
深度优先和广度优先
可以参考这篇文章
a*算法
可以参考这篇文章
b*算法
b*搜索相对于a*搜索速度快了几十倍,但是他不能够保证最优解,和贪心算法有些类似。
定义:
- 探索节点:起始探索节点为原点
- 自由探索节点: 还可以进行下一步的探索节点
- 绕爬探索节点: 如果前方有阻挡,探索节点将试图绕过阻挡,绕行中的探索节点称为绕爬节点
算法过程:
- 起始,探索节点为原点,向目标进发
- 自由节点在前进过程中判断前方是否有障碍
- 有障碍,则分出左右两个分支试图绕过障碍,绕过障碍后节点将变成自由节点
- 无障碍,向目标前进一步
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| bool map[boundary.height()][boundary.width()];
Node* begin_node = new Node(point, null);
map[point.x][point.y] = 1;
begin_node->direction = getDirection(begin_node, end_node);
free_nodes.push(begin_node);
while(!free_nodes.empty())
{
Node* node = free_nodes.pop();
Point dir_point = node->point + node->dir;
if(detectObstacle(dir_point) || map[dir_point.x][dir_point.y])
{
if(!climbPoint(node))
return -1;
free_nodes.push(node);
}
else if(node->point == dir_point)
{
return 0;
}
else
{
node->point = dir_point;
node->dir = getDirection(node, end_node);
free_nodes->push_back(node);
}
}
bool climbPoint(Node* current)
{
Point dir_point = node->point + node->dir;
while(detectObstacle(dir_point) || map[dir_point.x][dir_point.y])
{
bool success = false;
for(int i=0; i<4; i++)
{
dir_point = node->point + dirs[i];
if(!(detectObstacle(dir_point) || map[dir_point.x][dir_point.y]))
{
success = true;
current->point = dir_point;
current->dir = getDirection(current, end_point);
dir_point = current->point + current->dir;
break;
}
}
if(!success)
return false;
}
return true;
}
|
jps寻路
jps寻路部分参考文章
jps是a*算法的改进。在a*算法中,路径周围的点往往都会被选择,如图所示
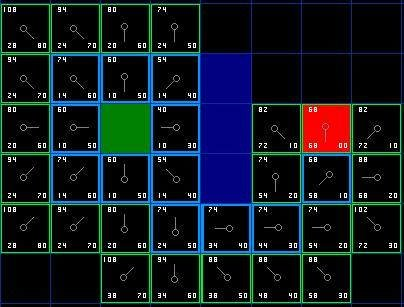
和b算法相比,a算法选择点的数量往往更多,并且可能会有多条等价路径。jps正是考虑到了这些缺点,将每个点的领居进行了约束,并且在没有遮挡的情况下只保存路径的起点和终点。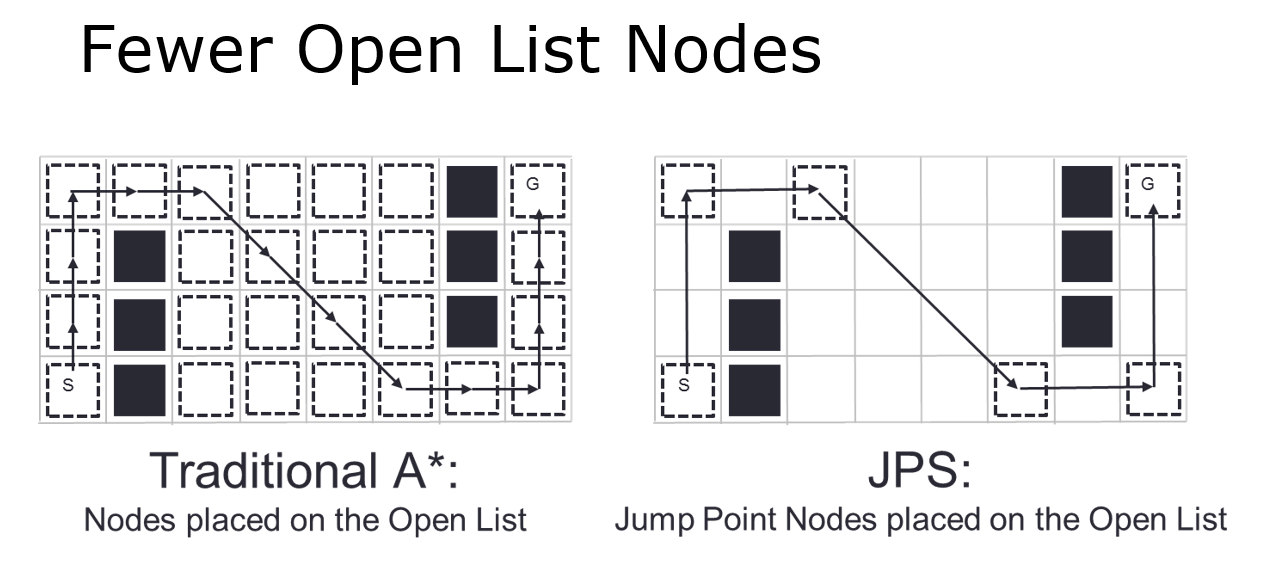
也就是说jps寻路只保存改变行走方向的拐点
一些概念:
- 强迫邻居: 节点 x 的8个邻居中有障碍,且 x 的父节点 p 经过x 到达 n 的距离代价比不经过 x 到达的 n 的任意路径的距离代价小,则称 n 是 x 的强迫邻居。也就是说p经过x到n的代价最小。如图中的红圈都是强迫邻居
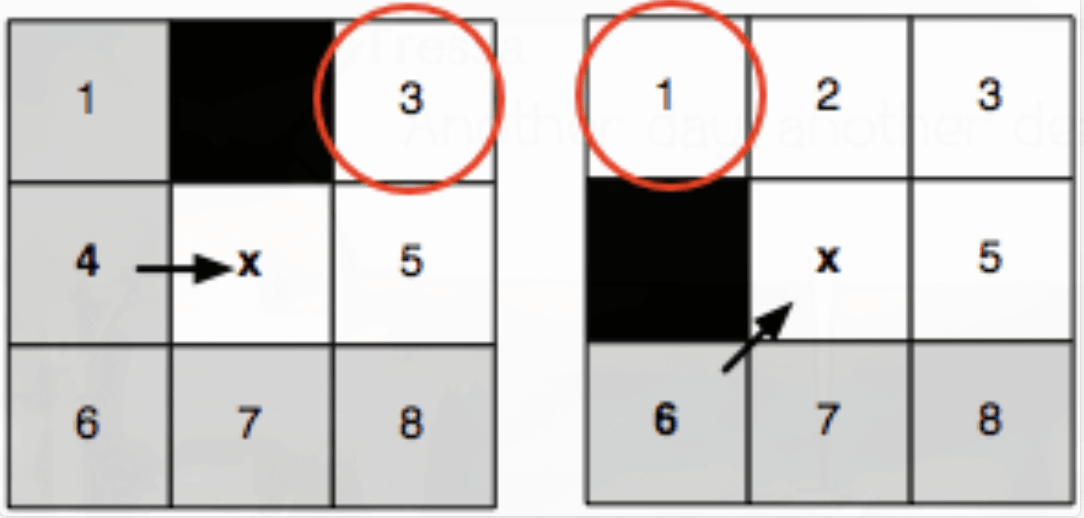
- 跳点: 跳点包含三种情况,存在三种情况中的一种则为跳点
- 是起点/终点
- 节点x至少有一个强迫邻居
- 如果父节点在斜方向,节点x在水平或垂直方向上有满足前面两个条件的点
jps算法过程:
- 选择一个权值最低的点开始搜索
- 搜索时,先直线搜索(一直搜索), 然后再斜向搜索(只搜索一步)。如果期间某个方向搜索到跳点或者碰到障碍,则完成当前方向的搜索,如果搜索到跳点则加入列表
- 如果斜向没有完成搜索,则在斜方向前进一步,重复上述过程
- 如果所有方向搜索完毕,则认为该节点搜索完毕(斜方向也碰到了障碍),移出列表
- 重复取权值最低的节点搜索