MPI编程
本文最后更新于 2021年4月24日 晚上
简介
MPI是一种编程规范,它的实现是一个库,主要在Fortran和c语言上实现。它的目的是实现进程间通讯。
MPI基本函数
开始与结束
- MPI_Init(&argc, &argv): 利用输入进来的参数进行初始化
- MPI_Finalize(): MPI终止时调用
1 | |
身份标识
- MPI_COMM_WORLD: 获得通信域(也就是同一组内的进程,例如上面mpirun -4代表启动4个进程,他们属于同一组)
- MPI_Comm_size(MPI_COMM_WORLD, &size): 获得进程个数,赋值给size
- MPI_Comm_rank(MPI_COMM_WORLD, &rank): 获得此进程在通信域内的编号,赋值给rank
数据类型
基本数据类型有: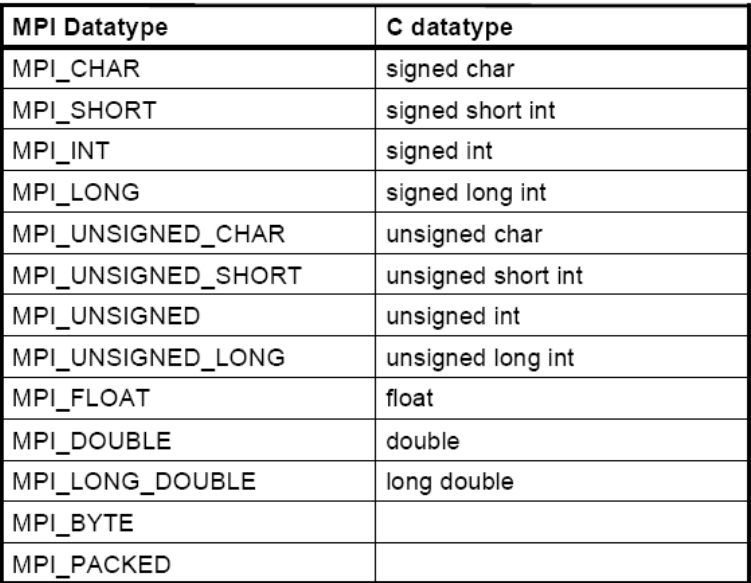
自定义结构体:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct
{
int a[4];
double b[4];
}node;
types[0] = MPI_INT;
length[0] = 4;
displacements[0] = 0;
types[1] = MPI_DOUBLE;
length[1] = 4;
displacements[1] = 4;
MPI_Type_struct(2, lengths, displacements, types, &buff_datatype);
MPI_Type_commit(&buff_datatype);
然后就可以使用buff_dtattype这种类型了,这种类型也就表示了node
信息传递
int MPI_Send( void *buff, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm):- buff: 是存储消息缓存的起始地址(一般用数组)
- count: 传递定义数据类型的多少项
- datatype: 传递的数据类型
- dest: 是目的进程的编号(由对方的MPI_Comm_rank获得的)
- tag: 消息标签,接收方的消息标签要和发送方的消息标签相同才可以接受,一两位目的进程可能不知接收一条信息,它需要标签进行区分。
- 标识通信域,一般使用MPI_Comm_WORLD
int MPI_Recv( void *buff, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status):- buff: 用来接收消息的缓冲区
- 接收的最大项数
- source: 消息来源进程编号
- tag: 双方约定的信号量(这个源和目的地都应该相同,不然收不到)
- status: 状态信息,包括消息的源进程标识,消息标签,包含的数据项个数等。Status.MPI_SOURCE, Status.MPI_TAG , MPI_Get_count(&Status, MPI_INT, &C)可以读出
1 | |
int MPI_Sendrecv(void *sendbuf, int sendcount,MPI_Datatype sendtype, int ,dest, int sendtag,
void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, int recvtag, MPI_Comm comm, MPI_Status *status): 它的作用是捆绑发送接收,他可以避免由于发送接收次序错误而造成的死锁。同时它可以接收单个MPI_Send发来的消息也可以呗:MPI_Recv接收到MPI_PROC_NULL: 虚拟进程,当一个进程向这个进程发送消息时,会立刻成功返回,接收消息时也会立刻成功返回并且缓冲区没有任何改变。它可以写在source或dest中
组通信
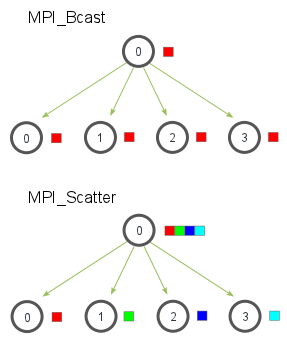
- MPI_Bcast( void* data, int count, MPI_Datatype datatype, int root,MPI_Comm communicator): 标号为root的进程给其他所有进程发送消息,包括他自己,对于root来说,data即是发送缓冲又是接收缓冲
1
2
3
4
5
6
7
8
9
10MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
do
{
if (rank == 0)
scanf( "%d", &value );
MPI_Bcast( &value, 1, MPI_INT, 0, MPI_COMM_WORLD );//其他进程也要写,用来接收
printf( "Process %d got %d\n", rank, value );
} while (value >= 0);
MPI_Finalize( ); - MPI_Scatter(
void send_data,
int send_count,
MPI_Datatype send_datatype,
void recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)- root发送给每个分组缓冲区中的一部分信息,非root进程会忽略发送缓冲。它是将每个接收缓冲区填满之后才会发给下一个进程,而不是平均分。
- MPI_Gather(
void send_data,
int send_count,
MPI_Datatype send_datatype,
void recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)- 只有root进程的recv_buf是有效的,其他可以随便传
- 它是接受所有进程的信息汇总到root进程中(包括它自己的信息).
- 接收信息是按照序号进行排列的,并且recv_count只需要填写一个进程接收的信息就可以了
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int *recv_buf;
if(rank == 0)
{
recv_buf = (int*)malloc(sizeof(int) * all * all);
}
int *send_buf = (int*)malloc(sizeof(int) * add_sum * add_sum);
int beginx = rank / sqrt_num * add_sum;
int beginy = rank % sqrt_num * add_sum;
int flag = 0;
for(int i=beginx; i<beginx+add_sum; i++)
{
for(int k=beginy; k<beigny+add_sum; k++)
{
send_buf[flag++] = i * add_sum + k;
}
}
MPI_Gather(send_buf, add_sum * add_sum, MPI_INT, recv_buf, add_sum * add_sum, MPI_INT, 0, MPI_COMM_WORLD);
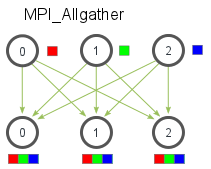
- MPI_Allgather(
void send_data,
int send_count,
MPI_Datatype send_datatype,
void recv_data,
int recv_count,
// v: int recvcnt, int disp
MPI_Datatype recv_datatype,
MPI_Comm communicator):- 每个进程都把自己的信息发给其他所有进程,完成之后所有进程都有信息的聚合
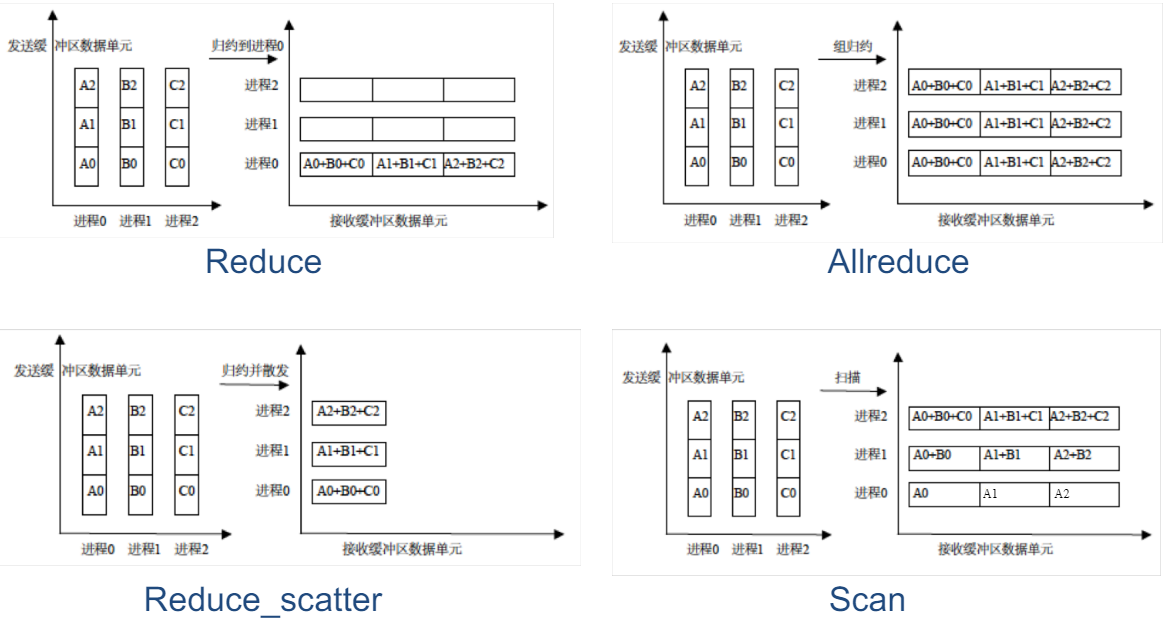
- MPI_Reduce(inbuf,result,count,datatype,op,root,comm): 进行聚合之后还进行了一次归约操作,归约操作有MAX, MIN, SUM, PROD, LAND, BAND(按位与), LOR, BOR, LXOR, BXOR, MAXLOC, MINLOC等。这是每一个数据每一个数据进行归约
- MPI_AllReduce: 和MPI_Reduce类似,没有root参数
- MPI_Reduce_Scattar(void send_data, void recv_data, int recvcounts, Op, Comm): 对数据进行归约之后再分给每个进程。
- MPI_Scan(void sendbuf, void recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm): 每个进程都对它前面的进程进行归约,类似前缀和
- int MPI_Alltoall(void sendbuf, int sendcount, MPI_Datatype senddatatype, void recvbuf, int recvcount, MPI_Datatype recvdatatype, MPI_Comm comm): 每个进程把第i块数据发送给第i个进程,又从第j个进程接收数据到自己的第j块中。
例如: 进程1把自己第二块数据发送给进程2, 进程2接收到来自进程1的数据放到 第一块中,类似于矩阵转置。
- MPI_Comm(Comm): 等待同一群组中所有进程到达屏障时候才进行下一步操作

多线程MPI
MPI_INIT_THREAD(int *argc, char ***argv, int required, int *provided)- required: 是线程的需求级别,它决定了那些线程可以进行MPI通信
- MPI_THREAD_SINGLE: 单线程
- MPI_THREAD_FUNNELED: 只有主线程可以进行MPI通信
- MPI_THREAD_SERIALIZED: 同一时刻只有一个线程可以进行MPI通信
- MPI_THREAD_MULTIPLE: 任何线程都可以随意进行通信
- provided: 可以提供的线程
- 设定了级别之后就可以在MPI内部用多线程了
- required: 是线程的需求级别,它决定了那些线程可以进行MPI通信