Python 爬取
本文最后更新于 2020年7月16日 上午
requests
requests用来爬取网站上的信息。有七个主要方法
- r = requests.get(url, params, ** kwargs): url是你想爬取网站的url。通过get构造了一个向服务器请求资源的Request对象。返回一个包含服务器资源的Response对象。
- head(): 获取网页头部信息
- post(url, data, json, kwargs): 在后面添加数据。默认如果是列表等会存储到form字段下,如果是字符串会存在data字段下
- put(): 覆盖网页某一字段数据。例如上传字符串会把data字段覆盖
- patch(): 删改某一位置信息(和put的区别是put必须全部删除,patch只需要修改需要改的部分)
- delete(): 删除url处的资源
- request(method, url, ** kwargs): method有七种,分别是’GET’,’OPTIONS’等,注意其中delete是小写。
kwargs参数(get,put, patch要比request少params,head,delete相同,post11个):
- params: 输入参数
例子 
- data: 提交资源,一般用用字典的形式
- json: 可以作为request的内容
- headers: http头字段
- cookies:
- auth: http认证功能
- files: 传输文件时使用
- timeout: 设定的超时时间
- proxies: 设定访问代理服务器
- allow_redirects: 默认是True。重定向开关
- stream: 是否对获取内容立即下载。默认立即下载
- verify: 认证SSL证书字段
- cert: 保存本地ssl路径字段
Response对象属性:
- status_code: 200表示成功,404表示失败(不是200就是失败)
- text: 爬取内容的字符串形式。
- encoding: 猜测的编码形式。这是从服务器的charset字段获得的。如果服务器中没有charset字段,那么会返回ISO-8859-1
- apparent_encoding: 备选编码形式.它是根据内容分析的(可能这个更加准确)
- content: 爬取内容的二进制形式
- request: response对应的request对象
爬取模板
requests异常种类: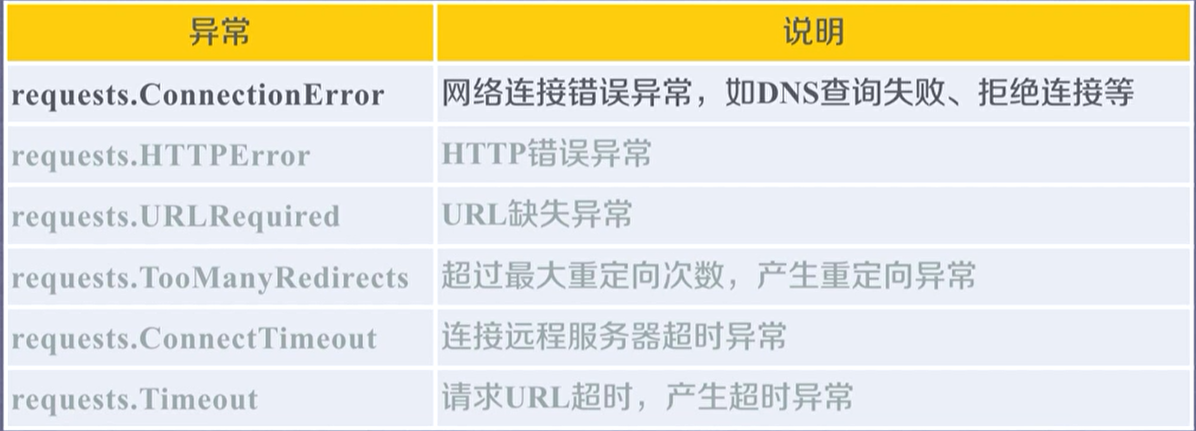
模板:
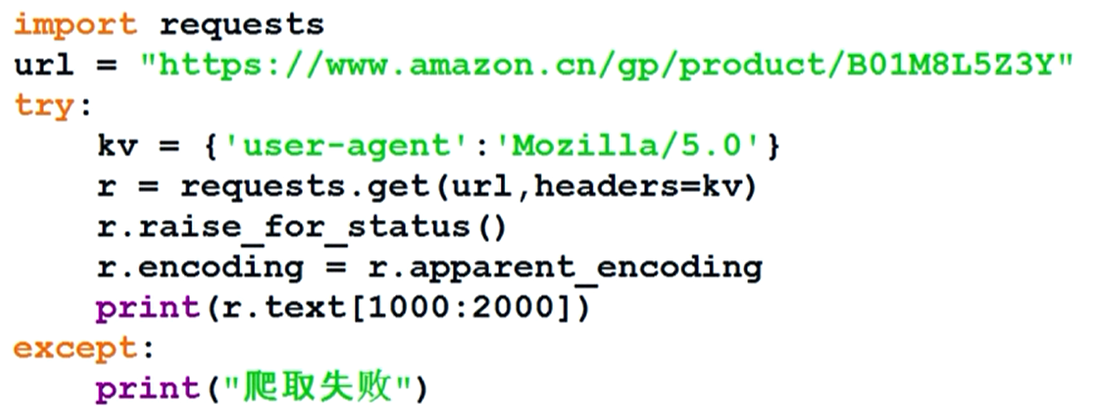
有些网页会拒绝爬虫的爬取,这个时候我们可以通过更改头部信息让我们看上去是浏览器爬取。模板为:
想要运用爬虫使用搜索引擎。首先要知道搜索引擎的接口,百度的接口是http://www.baidu.com/s?wd=keyword.360的接口是 http://www.so.com/s?q=keyword。其中keyword就是我们要搜索的内容。所以我们只需要在搜索时让url加上wd或q字段即可。
模板:
获取图片要用二进制读取的方式,模板为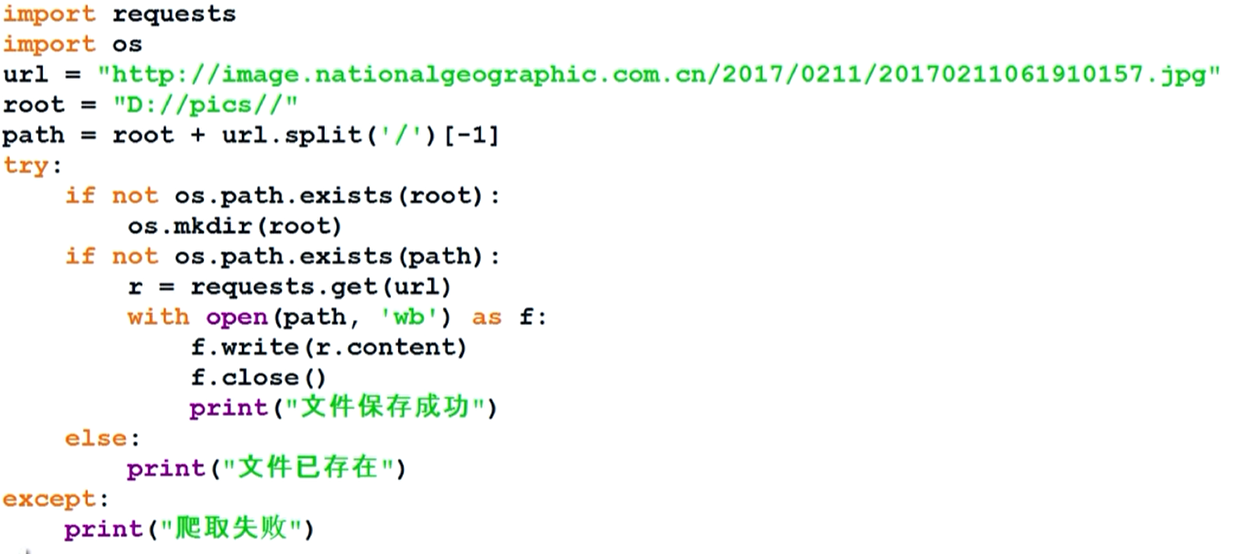
ip138是一个用来查询ip内容的网站。它的接口是"http://m.ip138.com/ip.asp?ip=..."于是我们可以通过这个接口去访问ip地址的内容。
模板: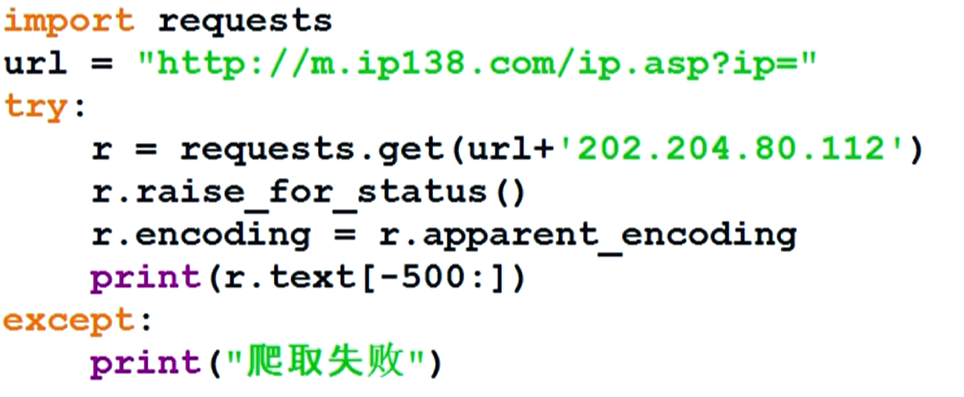
beautifulsoup4
beautifulsoup4可以用来解析html和xml。
导入: import bs4或from bs4 import Beautifulsoup
基本元素:
- Tag: 标签,如
<></> - Name: 标签的名字,如
<p></p>中的p - Attribute: 标签属性,如
<img src="..." alt="...">中的src和alt。它是一个字典类型,可以用<tag>.attrs访问 - NavigableString: 两个标签之间的字符串。用
<tag>.string访问 - Comment: 标签中间字符串的注释
一些函数:
- prettify(): 在标签之间添加换行符,让html文本易读。
- find_all(name, attrs, recursive, string, ** kwargs); 查找所有标签,返回列表,它有一种简写形式,标签(…),因为它十分常用。name是标签名字。attrs是对某一属性值的检索(如果某个标签有这个属性返回的还是这个标签)。recursive是是否对所有子孙进行搜索,默认是True。string是检索两个标签之间的字符串。
- find(),find_parents(),find_parent(),find_next_siblings(),find_next_sibling,find_preivous_siblings,find_previous_sibling(): 这些方法的参数和使用方法相同。其中find()只返回第一个结果并且是字符串类型。
解析器: 
例:1
2with open("F:/html/test.html", encoding='utf-8') as f:
soup = BeautifulSoup(f, "html.parser") # soup代指这个文档,算作一种标签
标签树的遍历
任何html文档都可以看成是一个标签树,树的根节点就是,因此我们可以从根节点出发得到整个标签树。
可以通过soup.html获得html标签。然后标签有如下属性:
- contents。子节点列表。\n也在列表中
- children。子节点迭代类型,用于循环遍历儿子节点
- descendants。包括所有的子孙节点,用于循环遍历
- parent。 父亲标签
- parents。 所有前辈
- next_sibling: 返回html文本顺序的下一个平行标签(也就是父亲节点相同)。navigable_string也在列表中
- previous_sibling: 返回html文本顺序的上一个平行标签
- next_siblings
- previous_siblings
正则表达式
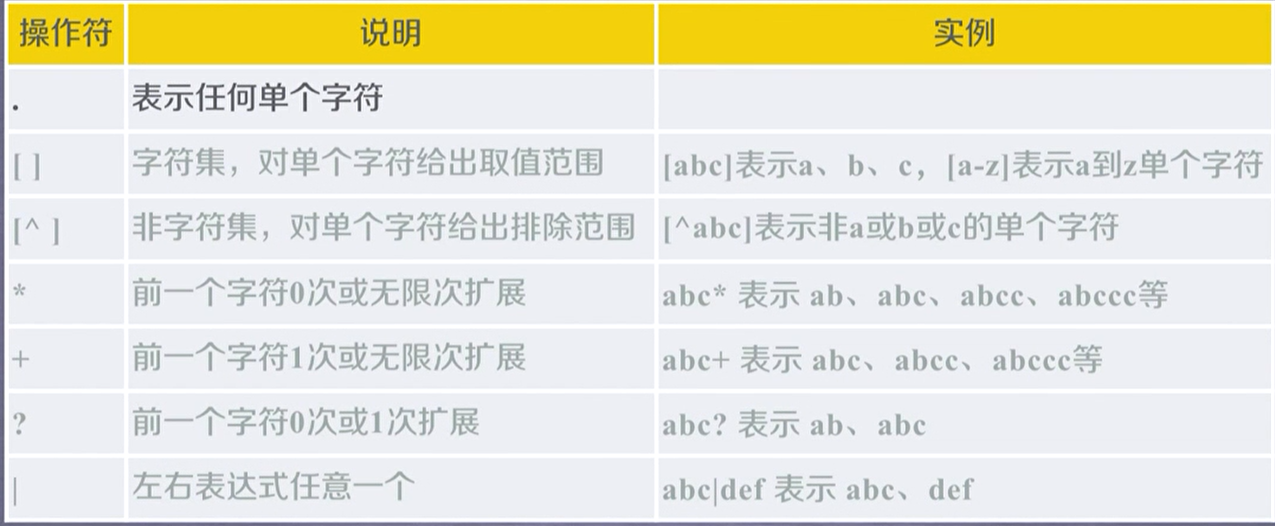
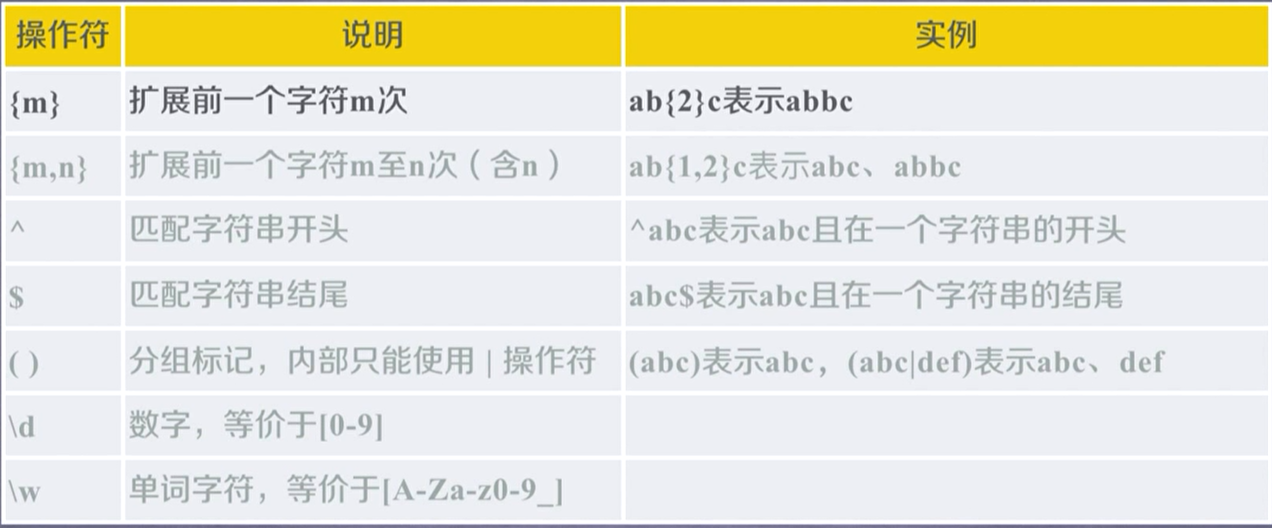
例如: 0-99表示 [1-9]?/d
python使用rowstring类型来表达正则表达式,即r’…’。这种String不会出现转义现象
函数:
- re.compile(pattern, flags=0): 把正则表达式编译成对象,便于多次使用。形成对象之后就可以使用下面的六个方法,都是相对的少了pattern参数

- search(pattern, string, flags=0): pattern是正则表达式字符串后者原生字符串。因为原生字符串有些字符要转义,比较麻烦。String是要搜寻的文本,flags是控制标记
- match匹配的字符串必须是从字符串开头开始。例如r3,如果我们用match搜寻数字,会返回空,因为数字不是从开头开始的。
- split(pattern, string, maxsplit=0, flags=0): maxsplit是最大分割数,多余的部分将作为最后一个元素输出。split函数会去掉匹配上的部分,然后剩下的部分用一个列表输出,maxsplit就是最多去掉多少个匹配的
- sub(pattern, repl, string, count=0, flags=0): repl是替换字符串,count是替换次数
 这是flags常用标记
这是flags常用标记
match对象的属性:
- string: 待匹配的文本
- re: 匹配时用的正则表达式
- pos: 正则表达式搜索文本的开始位置
- endpos: 结束位置
match的方法:
- group(0): 获得匹配后的字符串
- start(): 匹配字符串在原来字符串的开始位置
- end(): 结尾位置
- span(): 返回(start(), end())
如果没有匹配上,会返回一个空指针
python默认是贪婪匹配,即返回多个匹配结果,例如search返回的就是最长的那个
如果我们想匹配最短字符串,就需要在匹配多个字符的后面加上一个问号。例如:
*?、+?、??、{m, n}?