语义消歧
本文最后更新于 2024年10月1日 上午
概念
很多词语在不同语境下有不同含义,我们需要确定在某种语境下具体的含义。
语义消岐(WSD)定义: 确定一个歧义词在某种语境下应该使用哪种语义
消岐面临的三个问题:
- 判断一个词是否是多义词
- 对不同多义词的含义进行区分
- 确定在不同语境下应该使用哪种语义
基于贝叶斯的消岐
假设一个词有多个意象$s_1 s_2 .. s_n$,上下文(句子)C$w_1 w_2 … w_n$需要确定在该语境下使用哪种语义,即:
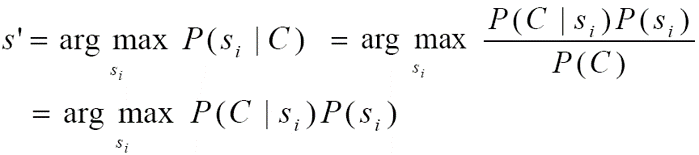
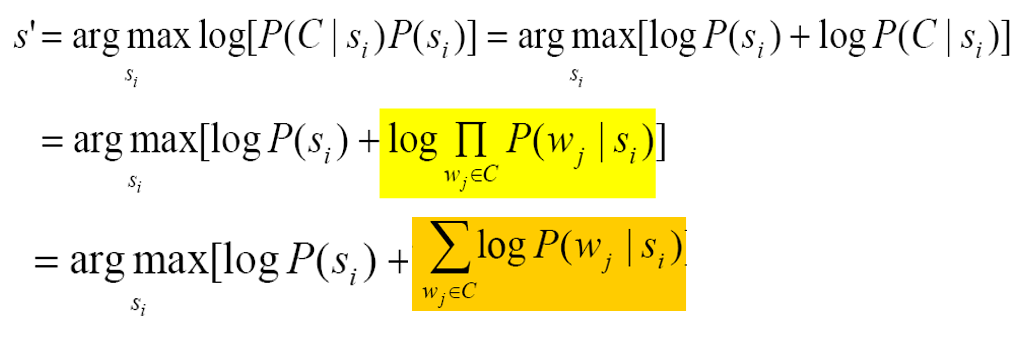
其中$P(s_i)$是这个词义出现的概率
基于互信息
互信息是使用另一个信息来表示当前信息。例如想知道当前词的语义信息,我们可以根据上一个词的时态或者是语态。
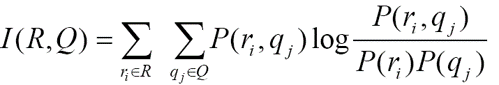
设一个中文词在英语中有若干译词$t_1 t_2 … t_n$,并且这个中文词有若干含义$v_1 v_2 … v_n$。
算法过程为:
- 随机的将t分成两类,记为R = {$r_1 , r_2$}
- 将v分成两类Q = {$q_1 , q_2$},使得I(R, Q)的值最大,再根据Q调整R的分类直到I(R, Q)变化不大为止
例如:


然后看这个多义词的上下文环境,如果获得了v在q1中,那么选择第一个意向,在本例中是读。
基于词典的消歧
词典中词条的定义就可以作为判断语义的一个很好的条件。
算法过程:
- 假设该词在词典中有若干义项($s_1 , s_2 … s_m$)
- 每个义项在词典中会用一些词进行解释,设词的集合为$D_1 , D_2 , D_3 … D_m$,对于单个解释来说,里面会有若干个词${a_1 , a_2 … }$
- 而这个词在上下文中出现时,先后也有一些词$v_1 v_2 …$,对于每一个词词的释义可以为$E_1 , E_2 …$
- 每个$si$的得分为:$Score(s_i ) = D_i \cap (\bigcup{vj \in C} E{v_j})$.含义也就是其他词的解释中出现了目标词的释义相同的词的数量。
这种方法只是一种非常粗略的方式,出现错误的可能性较大。
基于义类词典
因为多义词是通过上下文进行区分的,因此可以根据上下文的内容判断当前的语境从而判断这个词的含义。这里是通过划分义类来划分语境的。例如工具/仪器类,天文类等。
算法过程:
- Weight(w) = $log(\frac{P( w | R)}{P(w)})$。其中p(w | R)是w出现在R类中的概率,p(w)是w出现在训练语料库中的总概率
- 通过上述算法计算出每个词在每个类中的概率,之后计算判断每个词的含义时只需要计算这句话在每个义类中的权重(累加)从而得知