tensorflow
本文最后更新于 2025年11月27日 中午
本篇博客基于此。感谢龙龙老师提供的免费资料
tensorflow基础
数据类型
- 标量(Scaler): 单个实数,例如1.2,3.4等,维度为0,shape为[]
- 向量(Vector): 相当于数组,n个实数集合,维度为1, shape为[n]
- 矩阵(Matrix): n行m列。维度为2, shape为[n, m]
- 张量(Tensor): 所有维度大于2的都可以叫张量(其实上面的也可以是), 张量的每个维度也可以称作轴(Axis)。tf的运算时基于张量的,constant和Variable函数产生的都是张量
例如:1
2
3
4
5
6a = tf.constant(1) #创建标量
x = tf.constant([1. ,2 , 3]) #创建向量
print(x)#输出为<tf.Tensor: id=165, shape=(3,), dtype=float32, numpy=array([1 , 2 , 3], type=float32)>
m = tf.constant([[1, 2], [3, 4]])#创建矩阵
constant是创建一个常量,
tf.Variable()创建的是一个可以优化的张量。他在基础数据类型上添加了name, traiable等属性来支持计算图的创建
- string: 我们也可以创建字符串类型的常量或变量,同时也可以使用tensorflow提供的字符串处理函数如join(), lower(), length(), split()等
例如:1
2
3
4
5a = tf.constant('Hello, Deep Learning.')
print(a)
<tf.Tensor: id=17, shape=(), dtype=string, numpy=b'Hello, Deep Learning.'>
tf.string.lower(a)
- Boolean: 可以使用上面类似的方式创建Boolean类型,注意tf的bool和python的bool并不等价
1 | |
精度
常用的精度有tf.int16, tf.int32, tf.float16, tf.float32, tf.float64(double)
我们可以在创建张量时指定数据类型,例如tf.constant(3.14, dtype=tf.float16)
我们可以通过dtype属性来读取精度。并且可以使用cast进行精度转换1
2
3print(a.dtype) #tf.float32
a = tf.cast(a, tf.float64)#转换精度
print(a.dtype) #tf.float64
张量的创建
- tf.convert_to_tensor(list): 从数组或列表中创建
- tf.zero(shape): 创建全零张量,例如tf.zero([3, 2]) 创建一个3 * 2的张量
- tf.ones(shape): 创建全一张量
- tf.fill(shape, value): 创建初始值全是某一个值的张量
- tf.random.normal(shape, mean=0.0, stddev=1.0): 创建正态分布的张量,mean是均值,stddev是标准差
- tf.random.uniform(shape, minval=0, maxval=none, dtype=tf.float32): 创建从minval到maxval均匀分布的张量
- tf.range(limit, delta=1):创建[0, limit),步长为1的整型序列
可以使用start/:end/:step的方式进行切片,例如x[:,0:28:2,0:28:2,:],这是一个四维张量
此外,可以使用...省略若干维度的数据。例如x[0:2,...,1:]
更改维度
我们知道,数据在内存中多个维度,都是一维线性存储的,我们平常使用的多个维度只是为了方便访问。例如x = tf.range(96)创建了一个96个数据的一维数组,但是如果shape是[2, 4, 4, 3]在内存中和这个数组完全相同。基于这点,我们可以进行reshape
- tf.reshape(data, newshape): 注意newshape的数据总量和原张量的数据总量要相同。以上面的数据为例,2 4 4 * 3 = 96,因此可以变换。
- tf.expend_dims(x, axis): 在指定维度之前插入一个新的维度,但是并不会改变数据的存储。例如最开始的维度是[28, 28], tf.expend_dims(x, axis=2)后,维度为[28, 28, 1].
- tf.squeeze(data, axis): 只能删除长度为1的维度
- tf.transpose(x, perm=[…]): 交换维度,perm是现在的维度顺序(最开始是[0, 1,…]
和前面的reshape不同的是这里的维度数量没变,但是顺序改变,在内存中的位置实际上是变化的。例如,原来是[2, 32, 32, 3]的数据(例如这是图片数据,3是通道数),现在想变成[2, 3, 32, 32],可以tf.transpose(x, [0, 3, 1, 2]) - tf.tile(x, multiples=): 复制数据,multiples是复制的次数,等于1表示不复制.返回值是一个新的张量
例如通过tf.expand_dims(x, axis=0),变成之后tf.tile(x, multiple=[2, 1])变成 tf.broadcast_to(x, multiples=): 这也是复制数据的方法,但是和上面一个不同的是它并不会立刻复制,只有在需要的时候才会复制,这样可以使用一些优化手段避免不必要的数据io,提高了速度。
在不同维度的张量相加时隐式的有这个函数。例如shape为[2, 3]和shape为[3]的张量相加结果不会出错。这是因为shape为[3]的隐式使用了broadcast_to进行数据的复制,变成了[2, 3]。
自动扩展的方式是普适性。对于长度为1的维度,默认这个数据适合于当前维度的其他位置。对于新的维度,可以先扩展处长度为1的维度然后进行拓展。但是形如[32, 2]等有多个维度不是1的情况就无法自动扩展
对齐的方式是将维度向右对齐。然后将不存在的维度扩展为1,之后用已经存在的维度进行填充。

运算
加减乘除运算已经重载(乘是直接相乘而不是矩阵乘法)
- tf.math.log(x): 自然对数,如果是其他log可以使用换底公式$\log{a}x = \frac{\log{e}x}{\log_{e}a}$
@: 矩阵相乘运算符。此外还可以使用tf.matmul(a, b)。tensorflow的矩阵相乘可以是批量的形式,也就是当两个数的维度大于2时,会选择最后两个维度进行运算,前面的维度视为batch维度。a和b可以相乘的条件是a的倒数第一个维度必须和b的倒数第二个维度相等。
tensorflow进阶
合并与分割
合并指的是在某个维度上合并为一个张量。例如原来有一张照片它的shape为[1, 28, 28, 3],第一个维度是照片数目,第二个和第三个指像素点数目,第四个是三个通道。现在我想把它加入其他的一堆照片中[102, 28, 28, 3]。
合并可以使用拼接(concatenate)或堆叠(stack),拼接不会产生新的维度,而堆叠会产生新的维度。
- tf.concat(tensors, axis): 按照axis维度进行合并,除了axis维度不同外,其他维度都必须相同,以上面的例子说明
tf.concat([a, b], axis=0). - tf.stack(tensors, axis): 堆叠会创建一个新的维度,axis指定创建新维度的位置。堆叠的张量的维度必须相同。它的作用如把两张照片合并成一个相册。
tf.split(x, num_of_size_splits, axis): num_of_size_splits是分割方案,可以直接输入一个数字表示分割为几份,也可以输入一个列表具体的控制划分方式
例如我要把十份数据划分,可以直接num_of_size_splits=10,表示划分成10份,每份大小是1,如果原来是[10, 20, 5],那么现在是[1, 20, 5].如果num_of_size_splits=[4, 2, 2, 2],那么会产生4份,第一份有四个小块[4, 20, 5],后面三个都是两小块
数据统计
向量范数
向量范数是一种表示向量长度的方法,有以下几种范数
- L1范数:所有数的绝对值之和
- L2范数: 所有数的平方和再开根号
- $\infty$-范数: 所有数的绝对值中的最大值
可以通过tf.norm(x, ord)求得范数,其中ord=1,2分别是l1, l2范数,ord是np.inf时是$\infty$范数
可以使用tf.reduce_max, tf.reduce_min, tf.reduce_mean, tf.reduce_sum求最大值,最小值,均值,和。
例如:1
2x = tf.random.normal([4,10])
tf.reduce_max(x,axis=1)
比较
使用tf.equal()判断两个向量是否相等,他会返回一个和两个向量shape相同的向量,用true和false表示对应位置的数是否相同,然后使用tf.reduce_sum()就可以知道相同的个数了
填充和限制
- tf.pad(x, list): list是每个维度填充的数目,例如
{% post_link 0,0 %}表示第0个维度不填充,第一个维度左边填充2个,右边填充1个。第2个维度左边填充1个,左边填充两个 - tf.maximum(x, a): 将数据x的上限限制为a,同理还有tf.minimum(x, a)
- tf.clip_by_value(x, a, b): 下限为a,上限为b
tensorflow实现神经网络
- tensorflow.keras.layers.Dense(nodes, activation=): 这个函数会自动创建隐藏层的w和b,并且会自动进行矩阵计算。nodes是输出节点个数,activation是激活函数.我们可以使用类内部成员kernel和bias获得w和b
- tensorflow.keras.Sequential(): 一个容器,可以在里面创建多个层,只需要传入参数就可以自动计算
tf.keras.losses.categorical_crossentropy(y_true, y_pred, from_logits=true): softmax和交叉熵一起进行计算。y_true是真实值进行one_hot编码之后的值,y_pred是预测值,from_logits=true表示y_pred未经过softmax,为false表示经过了softmax(就不需要再进行一次softmax了),例子
在优化参数时,我们需要获得待优化的参数,可以使用Dense().trainable_variable获得
首先来看全连接层。
假设我们有两个样本$x^{(1)} = [ x_1^{(1)}, x_2^{(1)}, x_3^{(1)}], x^{(2)} = [ x_1^{(2)}, x_2^{(2)}, x_3^{(2)}]$,权重如下图所示
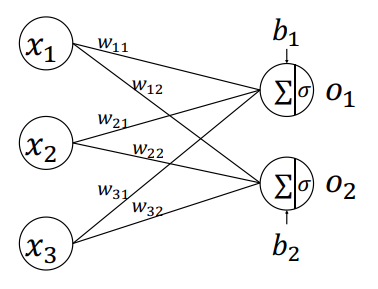
可以得知o1, o2为:
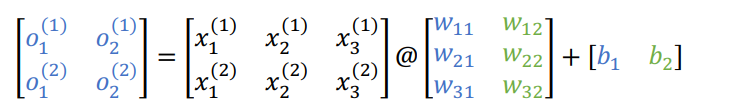
即$o_1 = x_1 w_1 + x_2 w_2 + x_3 * w_3 + b_1$的矩阵表示
用代码表示为:1
2
3
4
5
6
7
8
9
10
11x = tf.normal([2, 784])
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256])
o1 = tf.matmul(x, w1) + b1
o1 = tf.nn.relu(o1) #激活函数
也可以是
from tensorflow.keras import layers
fc = layers.Dense(256, activation=tf.nn.relu)
h1 = fc(x)
如果是多个层1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23手打就是创建多个w, b, o
from tensorflow.keras import layers
fc1 = layers.Dense(256, activation=tf.nn.relu)
fc2 = layers.Dense(128, activation=tf.nn.relu)
fc3 = layers.Dense(64, activation=tf.nn.relu)
fc4 = layers.Dense(10, activation=None)
h1 = fc1(x)
h2 = fc2(h1)
h3 = fc3(h2)
h4 = fc4(h3)
如果使用Sequential容器
from tensorflow.keras import Sequential
model = Sequential(
[layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(64, activation = tf.nn.relu),
layers.Dense(10, activation=None)]
)
out = model(x)
输出层1
2
3
4
5
6out = tf.random.normal([2, 10])#假设这是输出
y_onehot = tf.constant([1, 3])# 结果是1, 3
y_onehot = tf.one_hot(y_onehot, depth = 10)
loss = keras.losses.categorical_crossentropy(y_onehot, out, from_logits=True)
loss = tf.reduce_mean(loss)#计算平均交叉熵损失
反向传播可以自动求导,也就是1
2
3
4
5with tf.GradientTape() as tape:
上面的所有计算过程
grads = tape.gradient(loss, [所有变量])
变量.assign_sub(l * grads[0])
...
keras
层(layers)
在tensorflow.keras.layers下有许多常见网络层类,例如全连接层,激活函数层,池化层,卷积层等,
- tf.keras.layers.Dense(units, activation, use_bias, kernel_initializer, bias_initializer): Dense是全连接层,units是神经元数量,activation是激活函数,kernel_initializer和bias_initializer是初始化器。默认是
tf.glorot_uniform_initializer,可以使用tf.zeros_initializer
例如:1
2
3
4
5
6self.dense = tf.keras.layers.Dense(
units=1,
activation=None,
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
) - tf.keras.layers.Flatten(): 将input_shape变成一维的,例如input_shape是[28, 28],经过这个函数之后变成[784]
容器(Sequential)
容器是将多个多个层整合成一个层方便使用,它的原型是:1
2
3
4
5
6
7
8
9
10
11tf.keras.Sequential(
layers=None, name=None
)
例如:
network = Sequential([ # 封装为一个网络
layers.Dense(3, activation=None), # 全连接层,此处不使用激活函数
layers.ReLU(),#激活函数层
layers.Dense(2, activation=None), # 全连接层,此处不使用激活函数
layers.ReLU() #激活函数层
])
它可以使用add()动态添加layers,例如:network.add(layers.Dense(3))