虚拟内存
本文最后更新于 2024年10月1日 上午
基础
我们在生成程序的时候,会发现每个程序的起始地址都是一样的,那么这种一样的地址怎么赋给实际的物理地址上的呢?这就要依靠虚拟内存机制了。
虚拟内存着力于解决进程间内存分配的问题,并且它还有一个作用是使进程之间相互隔绝。例如不小心产生了一个野指针指向了其他内存的位置,但是实际上却不会破坏其他程序而只会破坏自己的程序,这是因为虚拟内存限制了每个程序所使用的空间,如果超出限制就会报错。
程序中所使用的空间叫做虚拟空间,一共有2的n次方。而系统上有一个物理地址空间。虚拟内存做的其实是把虚拟空间上的内存地址映射到物理空间上。在cpu中,有一个叫MMU的部件专门做虚拟地址和物理地址转化。
虚拟内存的组织形式
虚拟内存中的内存其实是按页进行划分的。这类似与磁盘中的扇区概念,即使那个扇区中只有一个字节的数据,取数据时也是把一个扇区全取出来。
虚拟内存页的大小一般是4kb到2mb之间。而物理内存也是按页进行分块,并且块的大小和虚拟内存页的大小相同。
其实把程序加载到内存时也不是一股脑直接加载的,而是一块一块逐个加载,并且如果内存满了还有块替换策略,这实质上是把内存当做一级缓存使用。
虚拟页有三种情况:
- 未分配的, 这部分内存就是虚拟内存预留出来的部分,例如malloc使用的空间,各个段之间预留出来的空间等。
- 缓存的, 就是加载到内存中的
- 未缓存的,是程序的组成部分但是还没有加载到内存中。
由于磁盘访问速度过慢(比SRAM小100000倍),所以我们要尽可能的降低未命中率。第一个办法就是增大每一块的大小(所以才会有一块甚至到2mb,有的小程序都没这么大)。第二个办法是全相连。全相连可以极大降低冲突不命中概率。第三个是使用复杂的块替换策略,这和缓存不同,因为缓存和内存之间速度也就十倍差距,所以块替换策略越简单越好,但是内存与磁盘间不命中惩罚太大,大到情愿花一些时间来找那个最不可能被替换掉。最后是使用回写策略。 缓存
页表
页表是存放于物理内存中的,页表中中的内容代表虚拟内存中这片地址是否被使用,如果被使用,还要存放实际的物理地址。
页表的大小是由虚拟内存大小和页大小决定的。假设虚拟内存大小矢2的n次方,页大小矢2的p次方,那么页表就有2的n-p次方条。这实际上是一种以空间换时间的策略。每个进程都有一个页表。
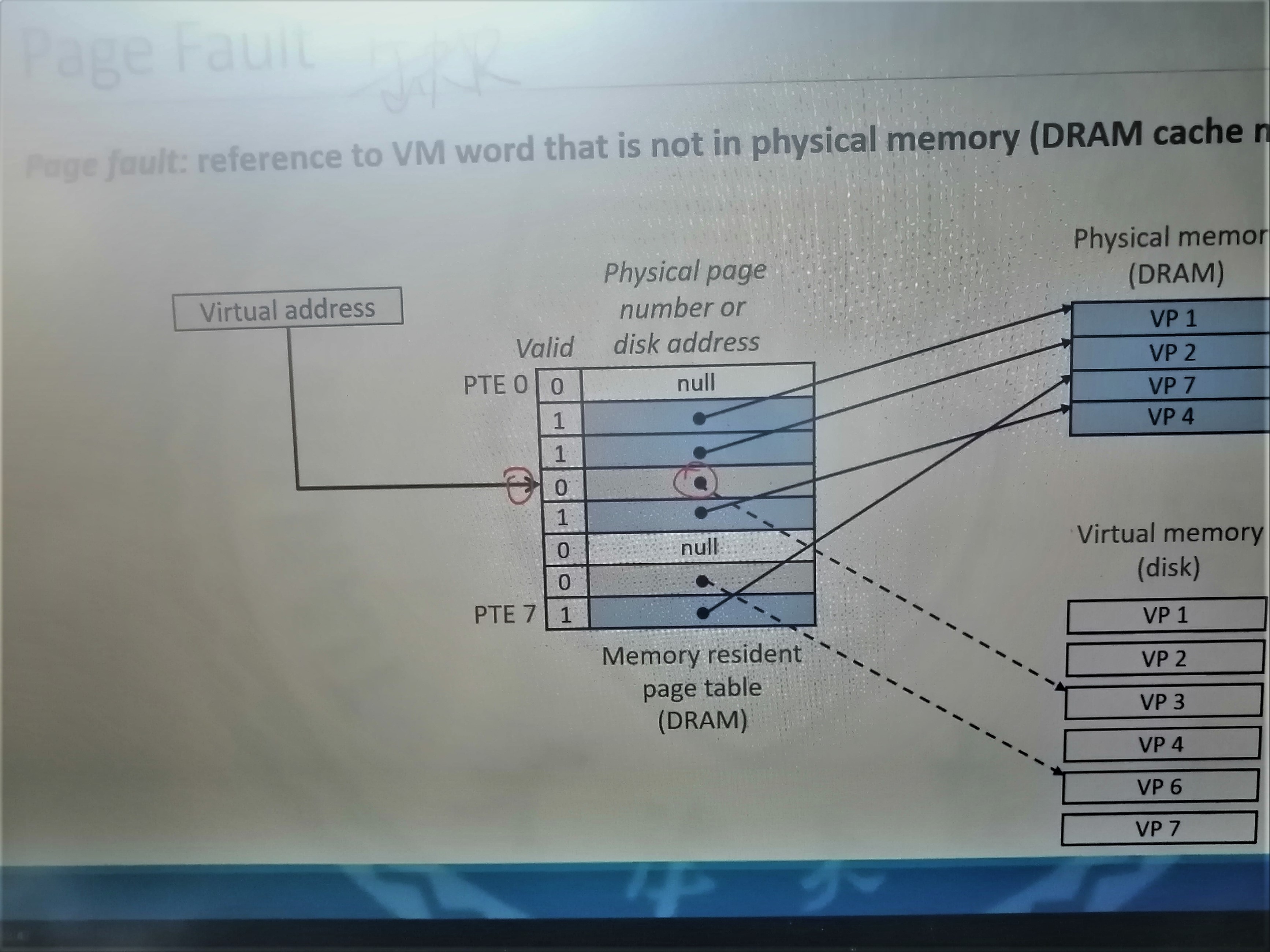
上图中左边就是页表,右下角代表磁盘。页表中灰色代表未缓存,未缓存的地址就指向磁盘。而白色代表未分配,地址直接是NULL。如果我们访问0,因为0是未缓存并且内存已满,所以要替换一块下来,假设替换第四块,那么就要把页表中三的地址给改为内存中的物理地址并且把4的地址改为磁盘中的地址。
所以当我们访问内存时,如果访问到未加载的地址,那么会触发故障异常,故障异常就会把磁盘中的内存加载进来并且重新执行这条指令。
如果我们加载到页表地址是NULL的地方,那么就会抛出segmentation fault。
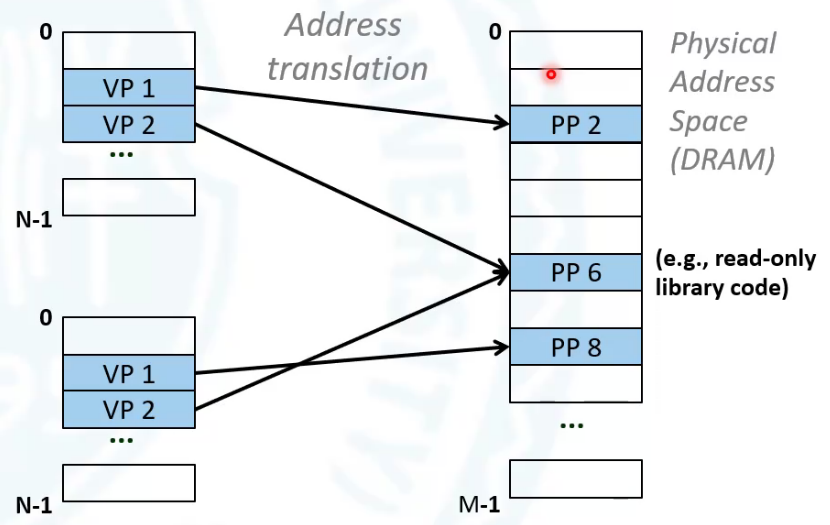
通过页表,我们可以让物理内存彼此分离。并且还可以让两个进程数据共享,这也使动态库可能实现。
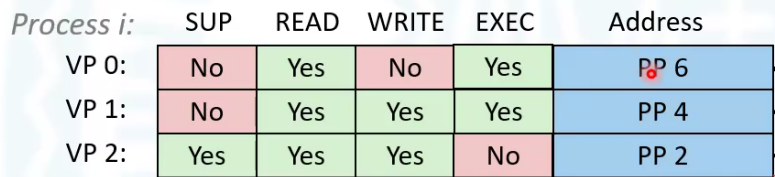
虚拟内存还提供了安全保护机制
这个是比较完整的页表,其中多了一些权限位。后面三个是读写和执行标志位,如果读的时候没有权限,那么就会抛出保护异常,这种异常一般都会终止程序。
第一个是模式标志位。有些操作系统专有的指令用户不能执行,有些专用寄存器用户不能访问。例如关机的指令即使用户特意编写也不会执行,因为它没有权限。
操作系统下的内存空间普通用户是没有办法去访问的。如果想调用操作系统的函数,可以使用陷阱异常,产生陷阱异常时,会转到特权模式。
地址翻译
首先虚拟地址的低p位是页内偏移,因为虚拟内存页的大小和实际内存页的大小相同,所以二者偏移量相同。虚拟地址高n-p位是页号。每一页的所包含的字节数是2^p,而页表页号数目是2^(n-p)
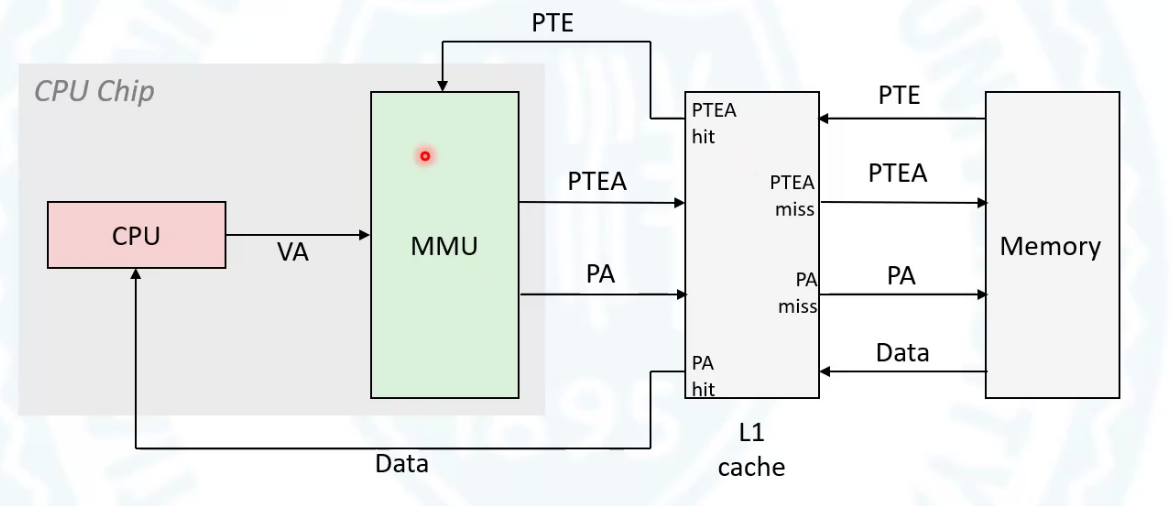
这张图表示了大致过程。cpu发出虚拟地址,mmu把地址解析成两部分(页号和页内偏移)。然后从内存中取出对应页号的地址(cpu中有页的基地址寄存器,页地址是根据页号* 每一个页表项的字节数+基地址得出)。然后mmu又根据取回来的页决定是否要去取内容。如果取,那么这个页中包含了物理页号,然后物理页号和偏移量直接合成得出实际地址。
如果标志位是0,那么还要到磁盘中去取出对应页放到内存中并且更新页表。
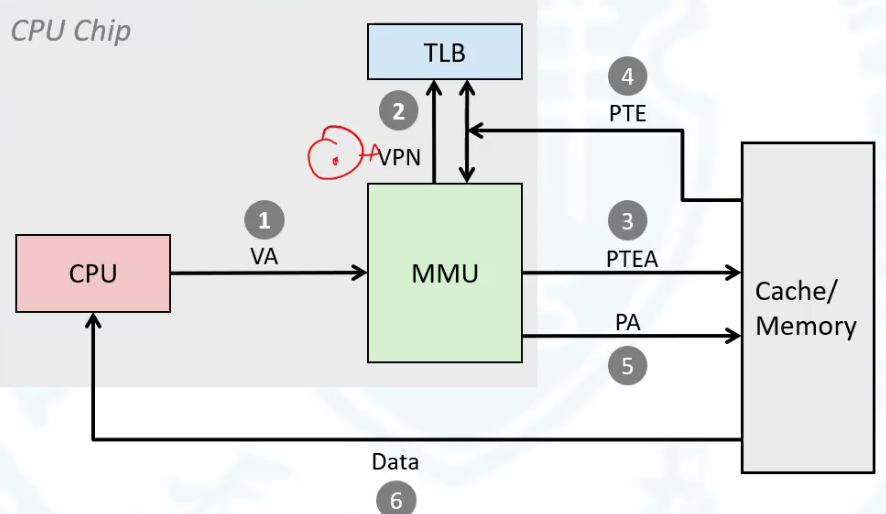
虚拟内存最大的问题就是显著增加了访问时间,本来只要访问一遍的现在要访问两遍。所以在mmu中又加了tlb寄存器专门用来存放页表。现在访问页表不用找内存了,直接找这个寄存器就可以了。如果没有找到再去内存中找并且更新tlb。
但是现代cpu都是多进程的。每个进程都有自己独立的页表,即使对应的内存相同可能标志位不同,也就是说每次更换进程都要把tlb清空一遍。一种解决办法是传给tlb页号的同时也传递一个进程信息,tlb也储存一个进程信息。
多级页表
假设虚拟内存大小是2的48次方,每页大小矢4kb,每个页表项8字节,那么页表大小矢2的39次方也就是512G。这在现实中显然是不可能实现的,所以要想办法把页表压缩。
我们很容易想到的一个办法是那些未分配的虚拟内存就不要建立页表项了,但是这样会带来一个问题。原来我们在查找页表的时候都是直接寻址,这是因为假设页表中每一项都存在,现在我们有一些项缺失了,直接根据页号查表的方法也就不行了,只有一个个比对,这样有增大了时间消耗。
我们可以建立一个多级页表,外层页表每一个页表项缓存的比较大,例如2mb甚至4Gb等,然后这一项中的内容不是物理页号,而是下一级页表的物理地址,之后下一级页表比上一级小,到最后一级就存储物理页号。
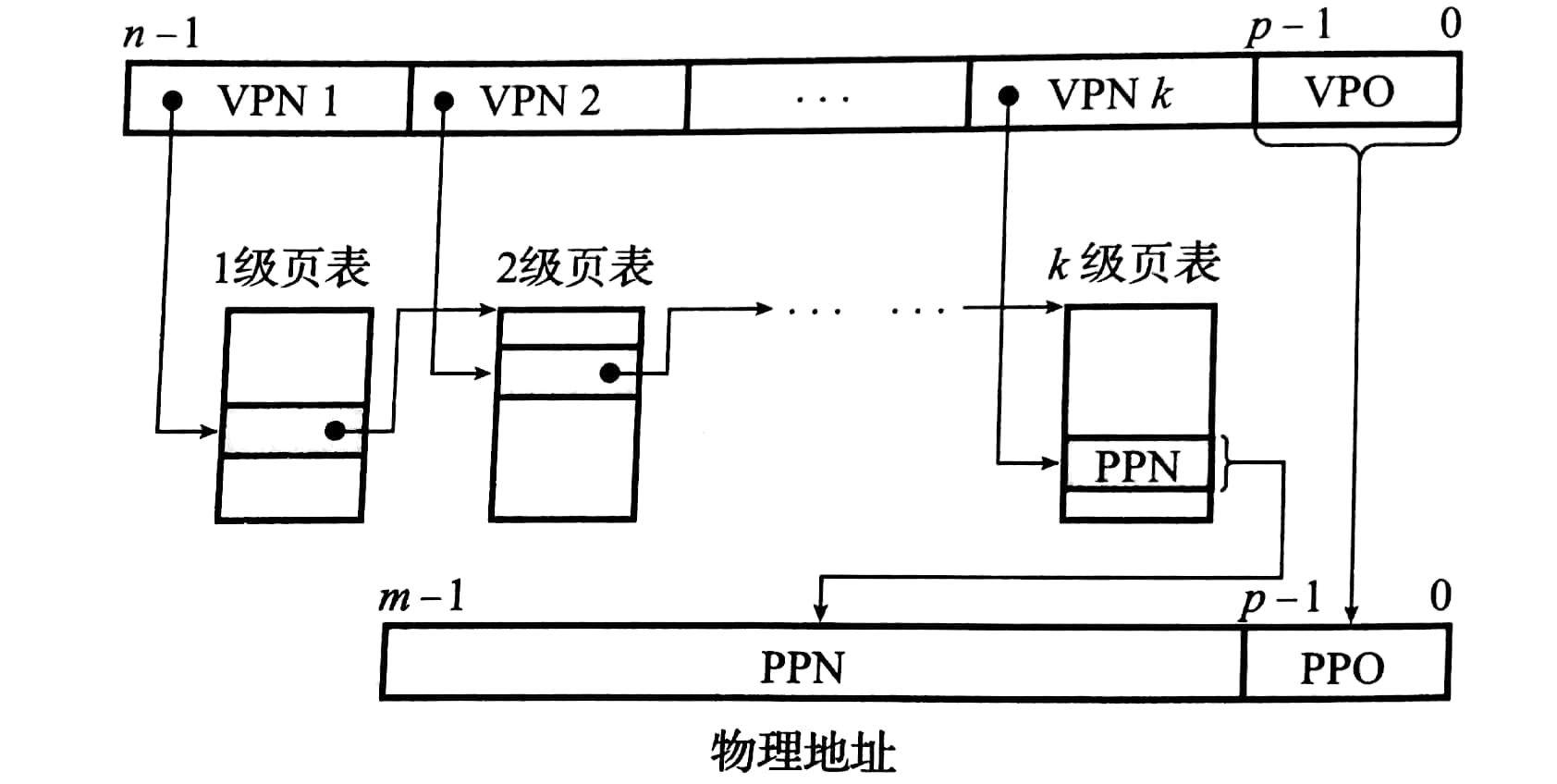
如上图,最外面一层就占着最高位,然后依次递减。这是因为一旦最外层选中了就说明最高几位是那几号,那么就不用管了。
这样看起来好像是用空间并没有减少,因为到最后一层还是要建立,并且中间几层还要额外消耗空间。实际上如果某个缓存块是未分配的,那么就不会建立下一级页表了。而外面几层页表锁包含的比较大,这样一下就可以排除几百个G的未分配空间。
页替换策略
- 最优页替换策略(OPT)
顾名思义,这种替换策略是最好的。它是将之后最少使用的页面替换出去,但是这种算法唯一的问题是他不可能被实现,可以作为一种理论判断依据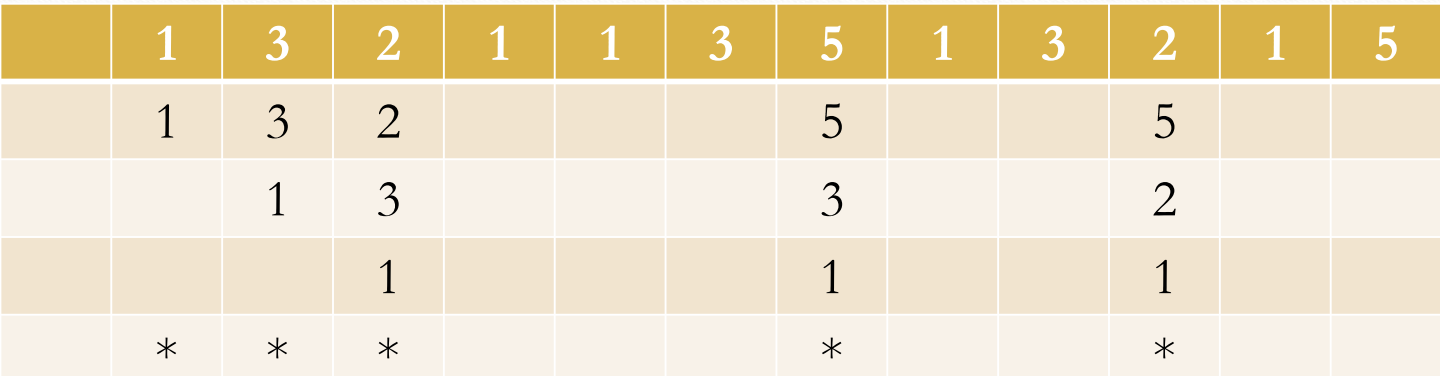
当5进来时,因为1即将也要进来,那么即使替换了1那么很快他也要被替换进来,所以不选择1,同样也不选择3,所以替换2.
- 先进先出策略
这种策略就是维护一个队列,将最早使用的页面替换出去。但是这种算法性能很差,甚至比随机替换的效果还要差。因为最早使用的页面不一定不重要,他可能还是一直在被使用
- 最近不使用(NRU)
这种策略是设置一个标志位,如果最近一个时钟滴答(一般是10-30ms)中被使用,那么就把它置1。替换时替换那些标志位是0的。
- 二次机会算法
这是在先进先出算法上改进而来。它同样也有一个最近是否使用的标志位,如果这个标志位是1,那么就把它置0并且把它放到队尾,如果标志位是0那么就替换。
- 时钟算法
这其实就是二次机会算法,只是组织方式由队列变成了循环队列。这样如果这个位是1只需要让指针加1就可以了,相当于把它放到队尾。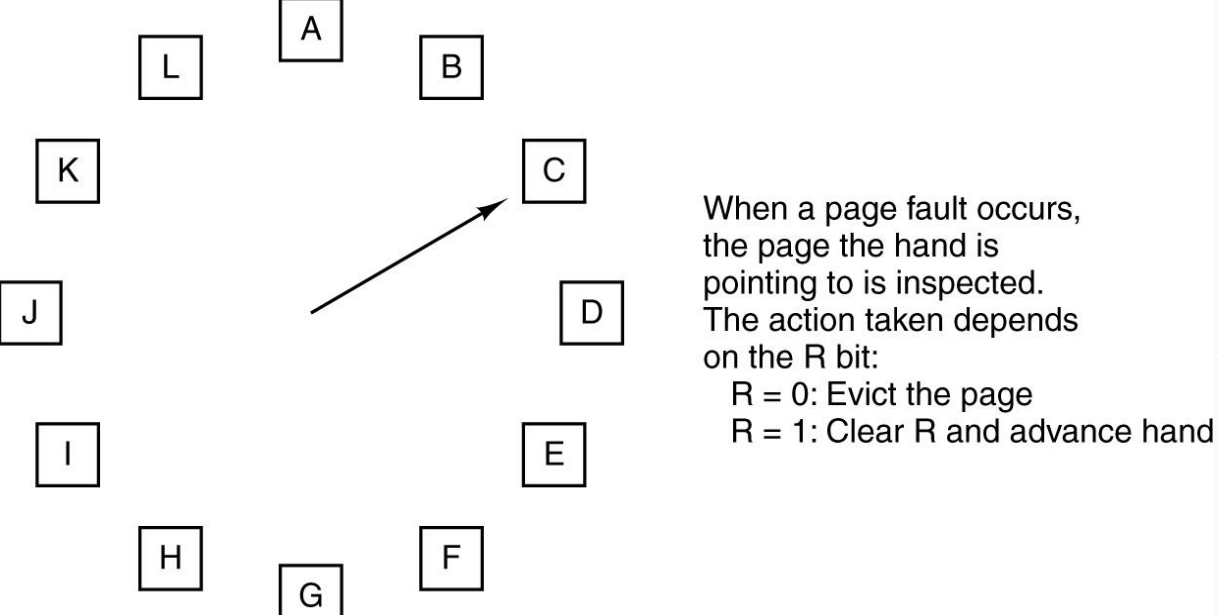
- 最近最少使用(LRU)
正如它的名字,就是将最近最少使用的页替换出来。它是除了最优页替换策略之外最好的算法,但是它几乎不可能实现。这里困难在于怎样定义最近和最少。为了定义它,产生了一系列近似策略
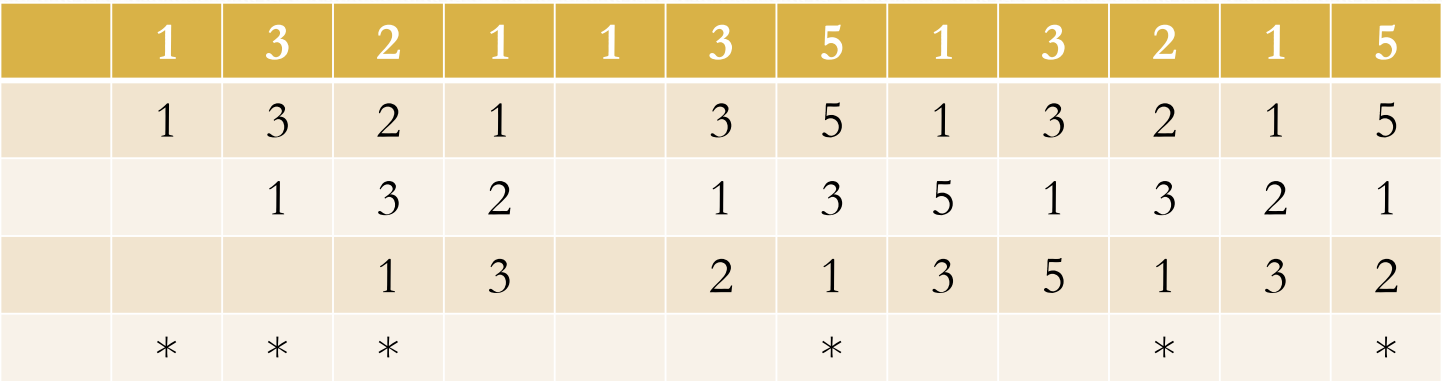 注意第二次出现1,他将1又放到了队首。
注意第二次出现1,他将1又放到了队首。
 .这种方法时如果访问该页面就将相应行置1,相应列置0.最后替换时选择0最多的行。
.这种方法时如果访问该页面就将相应行置1,相应列置0.最后替换时选择0最多的行。
因为将这行置1就会让这一行的1变得最多,可以表明是最近访问。而置0会让其他行的0的数目增多,相当于离访问时间更长。
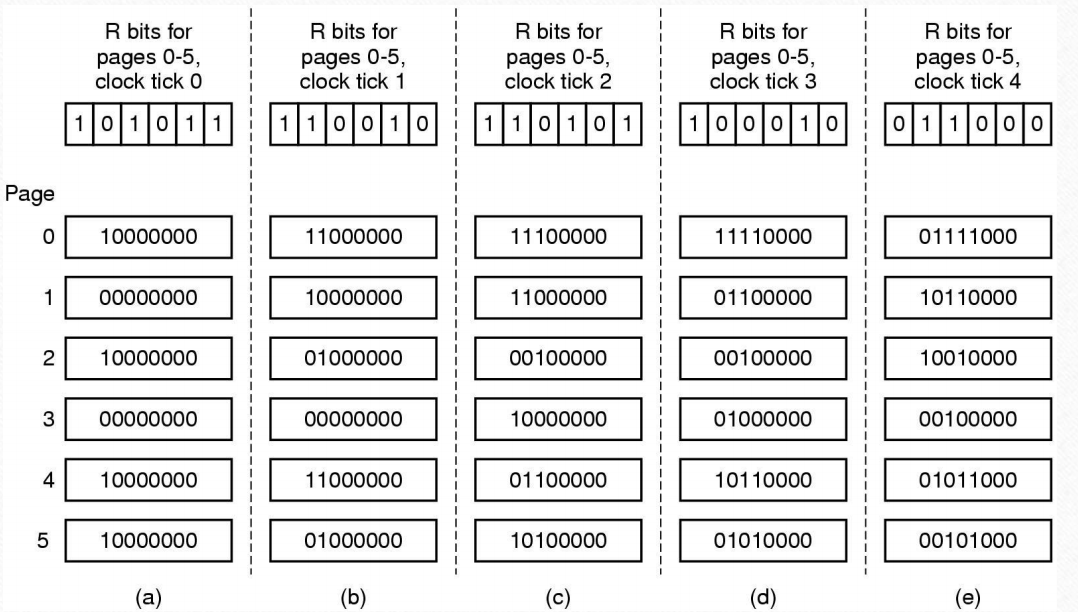
这种方法是将一个时钟滴答内访问过的页面最左边置1。到下次时钟滴答结束时全部右移一位,然后同样的方式置1.替换时只需选出值最小的替换即可。
要从左到右移位是为了保证最新一次更新的1产生的值是最大的,也就说明最近刚刚被访问。
- 工作集替换算法
工作集替换算法添加了一个该时钟滴答内是否访问的标志位和最近使用时间两个量。最近使用时间不是网络上的时间而是时钟时间(每经过一个时钟滴答就加1)。这种算法开销大所以介绍它的时钟形式。
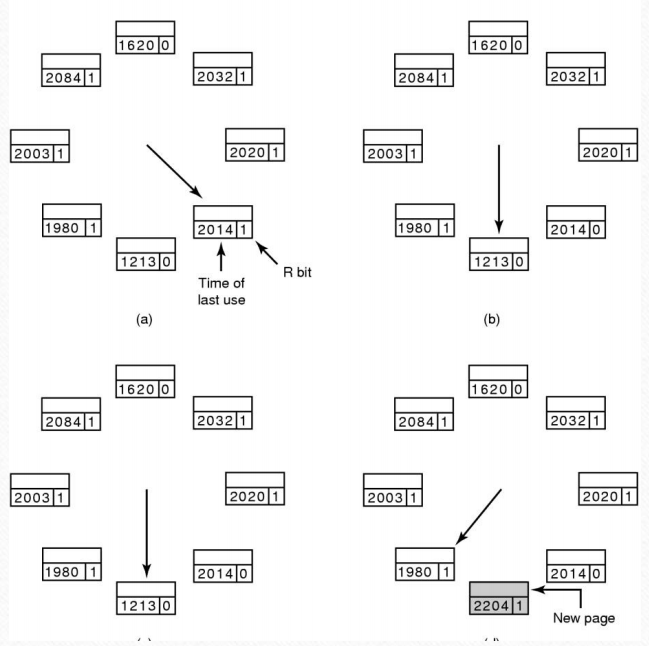
如果当前指针指向的页的标志位是1,说明这次使用了不应该抛弃,那么就将标志位置为0并且将上次使用时间更新为当前时间。
标志位是0并且时间差(当前时间-上次使用时间)小于设定的最大时间就将它记录,如果没有比他更差的就替换它。
时间差大于设定最大时间,那么就直接替换
倒排页表
由于64位虚拟空间过大,导致页表占用空间也很大。例如64位虚拟地址,页大小是4k,如果每一级页表用一个页装的话需要六级页表。因此便产生了倒排页表。
倒排页表是每一个物理地址对应每一个虚拟地址。例如8G的物理地址那么就需要8G个页表项。但是这种情况下虚拟地址转物理地址就变得困难,每次转换都必须要搜索一遍倒排页表从而找到这个虚拟地址对应的物理地址。
一种解决办法是使用Hash散列。通过特定的散列函数将虚拟地址映射到物理地址空间中,并且通过链表的方式解决冲突。
总结
首先补充一下前面tlb结构。tlb也是一个缓存并且是组相联结构,这就代表着传递信息中必须要包含组号,然后剩余的是标志位。

上图中tlbi就是组号,前面的是标志位。mmu传给tlb的只有vpn。
先是cpu发出虚拟内存地址,然后mmu开始解析,解析处vpn传给tlb,如果tlb解析成功那么再传给mmu物理页号并与vpo合成成物理地址。之后在把物理地址发给缓存。按缓存的方式处理。
如果tlb未命中,那么会到内存系统(包括缓存)中用页表基地址寄存器(CR3)找到最外层的页表然后一层层解析找到物理页号,然后把页号发给mmu的同时缓存那一片区域给tlb。
如果内存系统中也没有命中(未缓存或者未分配),那么就出触发缺页异常,通过缺页异常判断是未分配还是未缓存还是其他情况。
缺页异常时判断与一个链表有关。我们知道虚拟内存时分为若干个段的,每个段都有起始地址和终止地址还有一些权限标志位,这个链表就是存放这些信息。当2发生缺页异常时,会判断这个地址是否是在这些段中,如果不在,那么直接抛出Segmentation Fault。如果在那么判断标志位,如果判断不成功会抛出保护异常,如果判断成功了然后再去磁盘中取数据。
实例
S3C2440是一个嵌入式cpu,它最多使用两级页表,如果使用段(1Mb)则只有一级页表,如果使用页则有两级页表。页的大小有三种64kb, 4kb, 1kb。
转换过程:
- 根据页表基地址寄存器找到一级页表
- 如果是段描述符,则返回物理地址
- 如果是页描述符,则寻找下一级页表,并且如果第二个描述符还是页描述符,则返回物理地址
第一级中每一项都有4字节大小。

根据描述符中的最低两位,可以分为4种页表:
- 00: 无效
- 01: 粗页表
如果当前是粗页表,则[31: 10]称为粗页表基址(因为是2级页表大小为1kb因此低10位置0),可以根据它寻找二级页表,二级页表有256项($2^8$),而2级页表每一项表示4kb,因此一个粗页表项相当于表示了1Mb。 - 10: 段
[31: 20]称为段基址,低20位填0就是一块1Mb的空间,然后和虚拟地址低20位合并就是物理地址 - 11: 细页表
[31: 12]是细页表基址,因为要保证一个一级页表控制1Mb,因此二级页表有1024项,共4Kb。并且一个二级页表项控制1Kb.
二级页表也是类似的方式。

内存访问权限检查
内存权限检查是检查当前操作是否有读写权限。这在arm中由cp15寄存器C3、描述符的域、CP15寄存器C1的R/S/A位,描述符的AP位联合作用。
CP15寄存器C1中的A位表示是否对地址进行对齐检查(四字节低两位为0,两字节最低位为0),如果不对齐会产生alignment falut异常。MMU是否开启都可以进行对齐检查。
s3c2440中共有16个域,C3寄存器每两位对应一个域,含义为:
| 值 | 含义 | 说明 |
|---|---|---|
| 00 | 无访问权限 | 任何访问都将导致Domain fault异常 |
| 01 | 客户模式 | 使用段描述符、页描述符进行检查 |
| 10 | 保留 | 相当于无访问权限 |
| 11 | 管理模式 | 不进行检查,允许任何访问 |
页表中的域有4个bit,表示这块内存属于16个域中的哪一个。如果C3对应域为00,则直接Domain fault,如果为01,则使用描述符的ap进行检查.
large page是64kb页,每个ap控制16kb,ap3控制最高16kb。small page是4k页,每个ap控制1k。而tiny page只有1kb,因此只用一个ap控制
控制方式为AP,S,R位结合进行控制
| AP | S | R | 特权模式 | 用户模式 | 说明 |
|---|---|---|---|---|---|
| 00 | 0 | 0 | 无访问权限 | 无访问权限 | 任何访问都将导致Permission Fault |
| 00 | 1 | 0 | 只读 | 无访问权限 | 特权模式可读 |
| 00 | 0 | 1 | 只读 | 只读 | 任何写导致Permission fault |
| 00 | 1 | 1 | 保留 | - | - |
| 01 | x | x | 读/写 | 无访问权限 | 只允许特权模式访问 |
| 10 | x | x | 读/写 | 读 | |
| 11 | x | x | 读/写 | 读/写 | |
| xx | 1 | 1 | 保留 | - | - |
tlb和cache
tlb和前面介绍的过程相同。而cache具体分为指令cache(Icache)和数据cache(Dcache).
cpu启动时,Icache是关闭的,通过往CP15协处理器中寄存器1的第12位(Icr位)置1启动Icache。
Icache一般在MMU开启之后启动,此时页描述符中的C位(Ctt)来表示该内存是否可以被cache。读取指令时有三种情况:
- Cache命中且Ctt为1,从Icache读取指令
- Cache缺失且Ctt为1时,从主存读取指令,并且将该区域的8个word写入Icache的某个条目中。可以通过Pseudo-random算法或round-robin算法选择条目(替换策略)。可以通过CP15处理器中寄存器1的14位选择使用哪种算法
- Ctt为0时,从主存取指
Dcache也需要写入第2位(Ccr位)来开启,并且它必须在开启MMU后才可以使用。
| Ctt && Ccr | Btt | 访问方式 |
|---|---|---|
| 0 | 0 | 直接访问主存,不使用write buffer, 可以被外设终止 |
| 0 | 1 | 直接访问主存,使用write buffer, 读操作可以被外设中止 |
| 1 | 0 | 写通 |
| 0 | 1 | 写回 |