java 集合,列表,队列,映射
本文最后更新于 2021年3月14日 晚上
概念
- Set(集),集合中对象不以特定方式排序(有的实现类可以),没有重复元素
- List(列表),按照索引排序,可以有重复对象。List和数组类似。
- Queue(队列),先进先出
- Map(映射): 有键值对。没有重复键对象,可以有重复值对象
定义:
Set<String> set = new HashSet<String>();
Collection 和 Interator接口
Collection声明了上面这些数据结构(不包含map)通用的方法。
| 方法 | 描述 |
|---|---|
| boolean add(Object o) | 加入对象 |
| void clear() | 删除所有对象 |
| boolean contains(Object o) | 判断集合中是否有特定对象 |
| boolean isEmpty() | |
| Iterator iterator() | 返回一个Iterator对象(迭代器) |
| boolean remove(Object o) | |
| int size() | 返回数目 |
| Object[] toArray() |
返回一个数组,包含集合中所有元素 |
Set接口,List接口,Queue接口都继承了Collection接口。
Inerator接口定义了如下方法:
- hasNext():判断集合中的元素是否遍历完毕,如果没有返回true
- next(): 返回下一个元素。例如iter.next()是让iter这个迭代器进一位
- remove(): 删除由next()返回的元素
如果先用iterator()得到一个Iterator对象后,又用Collection的其他方法,再用next()可能会抛出ConcurrentModifcationException异常。
例:
1 | |
添加基本类型数据
实际上集合中只能存放对象。但是经常可以看到list.add(2)之类的操作。实际上在添加的时候已经隐式转换成Integer对象了。
Set
set本身是不排序的。但是它的实现类TreeSet具有排序功能。
一般用法
当添加一个新的元素时,首先要检查这个对象是否已经存在于集合中。如果存在就不添加。例如:
1 | |
HashSet 类
HashSet使用哈希算法存放集合中对象。具有良好的查找和存取性能。
前面说过在Object类中有hashCode()方法返回哈希值,而这个有使用hash算法存储的,所以判断两个对象是否相等还可以customer1.hashCode() == customer2.hashCode();
如果一个类覆盖了equals()方法,那么就应该实现hashCode()方法,保证党两个对象相等时,hashcode相同。
TreeSet类
TreeSet类实现了SortedSet接口,可以对集合中对象排序。TreeSet支持两种排序方法:自然排序和客户化排序。默认使用自然排序。
自然排序
TreeSet实现了Comparable接口的compareTo(Object o)方法比较集合中对象大小。如果返回值大于0,代表这个值大于o。只有实现了Comparable接口的对象才可以使用TreeSet进行排序。compareTo方法最好要从小到大进行排序,以便和其他的进行匹配。
下面列举了一些实现了Comparable接口的类
| 类 | 排序 |
|---|---|
| BigDecimal BigInteger Byte Double Float Integer Long Short | 按数字大小 |
| Character | 按字符 Unicode值 |
| String | 按字符串中Unicode值 |
如果是自己定义的类,首先要实现Comparable接口。并且最好也是通过返回值大于零小于零来判断谁大谁小的。
注意,如果把一个对象加入TreeSet并且修改它的属性TreeSet是不会重新排序的。所以适合排序的是不可变类。
客户化排序
客户化排序可以降序排序。首先实现java.util.Comparator
如果想实现降序排序,例如:
1 | |
Set有个构造方法 Set(Comparator comparaotr)可以使用Comparator来确定升序还是降序。
List
list的实现类有:
- ArrayList: ArrayList代表长度可变数组。ArrayList实现了RandomAccess接口,这个接口不包含任何方法,仅仅表示有良好的随机访问性能。
- LinkedList: 链式结构。LinkedList不仅仅可以做数组,还可以做堆栈,队列,双向队列。
访问元素和排序
list中get(int index)方法可以返回集合中索引位置的数。List中的iterator()和Set中的iterator()一样,也可以用来遍历。
此外,还可以用foreach来遍历
1 | |
至于排序,只能对集合中的对象按索引进行排序,如果想用其他方式,可以实现collections类和Comparator接口。Collections类中的sort方法可以用来排序
- sort(List list) 对List对象进行自然排序
- sort(List list, Comparator comparator)进行客户化排序
ListIterator 接口
List中listIterator()返回一个ListIterator对象,这个对象继承了Iterator接口,此外还有一些独有的方法
- add() 向列表中插入一个元素
- hasNext() 判断列表中是否还有下一个元素
- hasPrevious(): 判断列表中是否还有上一个元素
- next(): 返回下一个元素
- previous(): 返回上一个元素
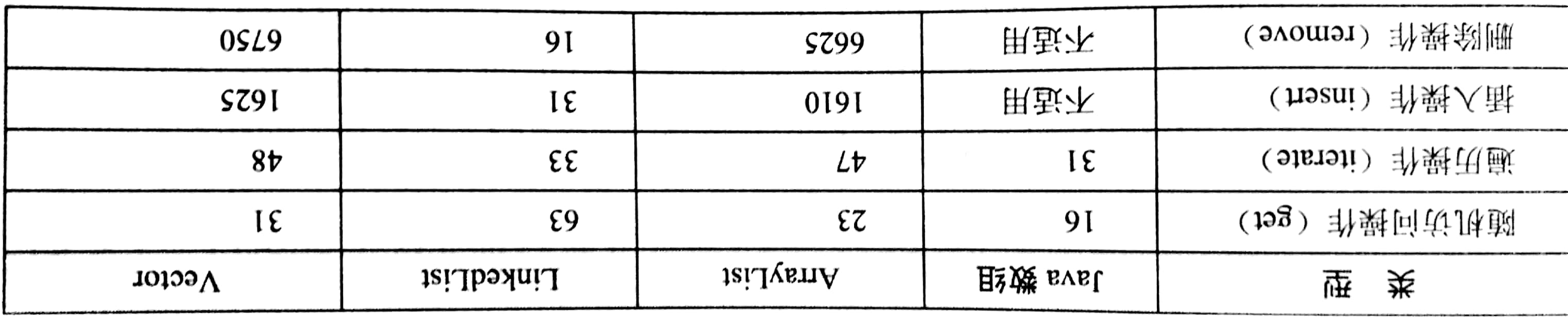
Queue
Queue提供了add()和offer()两种方法来从队尾加元素,如果是add队满就会抛出IllegalStateException,如果是offer()会返回false。
删除也有两种,一种是remove(),一种是poll()。如果是remove,队空后会跑出NoSuchElementException,如果是poll,空了会返回null
获取元素,一种是element(),一种是peek().如果不成功(队空),那么会出现和删除队空同样的情况。
Deque
Deque是一个接口
从头或尾添加元素
1 | |
如果队满,都会抛出IlllegalStateException.后两种方法返回false
删除
1 | |
和前面队空判断一样
获取1
2
3
4E getFirst()
E getLast()
E peekFirst()
E peekLast()
就是把上面的queue加了个first和last
LinkedList和ArrayList都实现了Deque接口,
PriorityQueue 优先队列
优先队列使用堆进行排序。并且因为要排序,所以想用优先队列要首先实现Comparable接口。
这里的remove总会首先删除最小的元素。
Map
定义: Map
其中type1是键类型,type2是值类型。
Map叫映射,就是给出键返回值。可以使用get(Object key)得到值。通过put(Object key, Object value)插入键值对。
Map的键不允许有重复,但是值可以有重复。
Map有两种常用实现,HashMap和TreeMap,HashMap用哈希算法来存取键对象,有良好的取性能。为了保证能正常工作,也要确保通过equals()比较为true时,两个对象返回哈希码相同。
TreeMap实现了SortedMap接口,可以对键进行排序。如果想进行客户化排序,可以调用TreeMap(Comparator comparator)构造函数。
Map的keySet()返回所有键对象的集合。
1 | |
set内的类型是Map.Entry,可以使用getKey()返回键,使用getValue()返回值。
Collections
适用于List的方法:
1 | |
适用于Map或Collection的:1
2
3
4
5
6
7
8
9
10
11
12
13Object max(Collection coll):返回集合中最大的元素
Object max(Collection coll, Comparator comp):采用指定规则进行比较,返回最大元素
Object min(Collection coll)
Object min(Collection coll, Comparator comp)
Set singleton(Object o): 返回一个不可变的Set
List singletonList(Object o) 返回不可改变的List
Map singletonMap(Object key, Object value):
Collection synchronizedCollection(Collection c): 在原来的基础上,返回支持同步的集合
Map synchronizedMap(Map m)
Set ...
List ...
Collection unmodifiableCollection(Collection c): 在原来结合的基础上,返回不可改变的集合视图
其他三个相同
前面的singleton是指这个集合中只有一个元素,并且不允许修改
而后面的unmodifiable是返回这个集合,但是如果原集合修改,这个集合也会跟着修改。不允许修改指的是不允许修改这个集合视图
线程安全的集合
在平常情况下集合的实现类都没有同步锁机制,这样可以加快速度。但是当有多个线程同时操作一个锁的时候就需要同步机制了。一种方式就是在可能导致问题的代码块用synchronized,另一种就是上面讲的方法。
集合批量操作
前面说的都是一次处理一个元素,如果要处理多个元素,可以采用Collection中的方法:
- boolean retainAll(Collection<?> c)修改集合,保留在c中的元素并删去其他元素
- boolean removeAll(Collection<?> c)删去集合中c的元素。
- boolean addAll(Collection<? extends E> c): 把c中元素加入到当前集合中
- boolean containsAll(Collection<?> c): 判断当前集合是否全部包含c
其他集合类
Properties是一种特殊的Map类。他可以用load()从输入流中读取键和值。例如;
1 | |
可以使用System.getProperties()返回一个Propertiese对象。这个对象中包含一系列系统属性。
BitSet表示一组boolean数据集合。类似于boolean[]数组。最小初始容量是64位,可以通过BitSet(int bits)设置初始容量。如果达到了初始容量会自动增加。
BitSet中有以下方法:
- set(int index) 把index位置的元素设置成true
- clear(int index) 把index位置的元素设false
- get(int index): 获得index位置的元素值
- and(BitSet bs): 与bs进行与运算,结果保存在当前BitSet中
- or(Bitset bs)
- xor(BitSet bs)
BitSet在c++中是返回二进制信息,在这里也可以有这个作用。可以自己建立byteToBitSet()计算出byte类型的二进制位,其他类型类似。printBitSet()打印BitSet二进制信息。
1 | |
枚举类型
位置: java.lang.Enum。这个类是抽象类
此外,还提供了关键字enum。例如 public enum Gender{FEMALE, MALE}
Enum类有如下非抽象方法(一般直接使用enum就可以了,也有这些):
- intcompareTo(E o) 比较当前常量与指定对象的顺序
- Class
getDeclaringClass()返回当前类型的class对象 - String name() 返回当前枚举常量的名称。例如调用Gender.FEMALE的name()方法,会返回FEMALE
- intordinal() 返回当前枚举常量在声明时的位置
- toString() 返回枚举常量的名称
static<T extends Enum<T>> T valueOf(Class<T> enumType, String name)返回制定枚举类型和名称返回的枚举常量- static Enum[] values() 以数组的方式返回所有的枚举常量
- range(from, to)用来迭代
range用法例如:
1 | |
枚举类型最大的作用就是可以用于switch,相当于扩充了switch的范围。
枚举类型构造方法
这个构造方法时private,或friendly类型的,例如:
1 | |
注意前面定义时的符号,如果是基础类型,那么最后一个不用跟任何符号,如果不是,那么最后一个必须要封号。并且前面只能是逗号
enum是构造对象时产生的,因此看起来相同的两个类型实际上比较时也可能不相同。
EnumSet和EnumMap
前面一个把枚举转化成集合,它的静态allOf()方法把枚举类所有常量实例存放到一个EnumSet类型的集合中,然后放回这个集合。
EnumMap转换成映射,它的EnumMap(Class
1 | |