应用层与HTTP协议
本文最后更新于 2024年10月1日 上午
HTTP协议
基础
HTTP由两个程序组成:客户程序和服务器程序。客户程序就是我们电脑上的程序
一个Web页面是由若干对象组成的,对象指的是一个文件,例如HTML文件,JPEG图像,Java小程序等。
多数Web页面包含一个HTML基本文件和几个引用对象。首先获得基本文件,基本文件之中又有链接到其他文件的URL,然后通过这些URL又获得其他文件。
例如有时我们直接从浏览器下网页文件打开后发现这个网页既没有排版也没有字体颜色,也没有图像。这里我们下载的文件就是HTML基本文件,如index.html.如果我们想要获得完整的页面就需要根据基本文件中的url再去获得其他文件然后通过浏览器合并到一起。
HTTP使用TCP作为传输层协议。TCP大致是首先发起一个与服务器的TCP连接,在链接成立之后就可以进行稳定的传输了。
非持续连接和持续连接
非持续连接指的是所有请求都通过单独的TCP连接发送,持续连接时所有请求都通过同一个连接发送。
HTTP的非持续连接
假设我们请求一个HTML基本文件和若干图形。并且这些对象位于同一台服务器上,那么非持续连接请求的大致过程是:
- HTTP客户进程在端口号80发起一个到服务器的TCP连接
- 客户通过套接字想服务器发送一个HTTP请求报文
- 服务器接收报文,查找对象之后通过TCP发送给客户
- 接收完成之后服务器进程同志TCP断开连接
- 客户进程接收到基本页面之后,获得其中的URL,再重复上述四个过程获得其他对象。
那么总的所需时间=发起TCP连接所需时间 + 请求文件建立TCP锁需时间 + 传输文件所需时间
一般来讲如果使用非持续连接的话会开5到10个并行的线程。也可以实行并行加载。
持续连接
非持续连接有这些缺点:
- 必须为每一个请求对象建立和维护一个连接。每一个连接都需要额外消耗用户和服务器资源,增加了服务器负担
- 其次每次建立TCP连接也需要时间
HTTP1.1持续连接可以让一个Web页面的所有对象通过一个TCP连接进行传输,这些请求可以同时发送并且不需要等待请求的回答。甚至可以对同一个服务器上的多个Web页面进行传输
HTTP/2允许相同连接中多个请求和回答交错。
报文格式
请求报文
1 | |
这是一个典型的报文:
- 请求行: 指第一行,有三个字段:方法字段、URL字段和HTTP版本字段。方法字段有GET、POST、HEAD、PUT、DELETE。URL字段要和host拼接起来才是平常熟悉的网址
- 首部行: 第一行后面的所有。Connection: close表示不要使用持续连接。
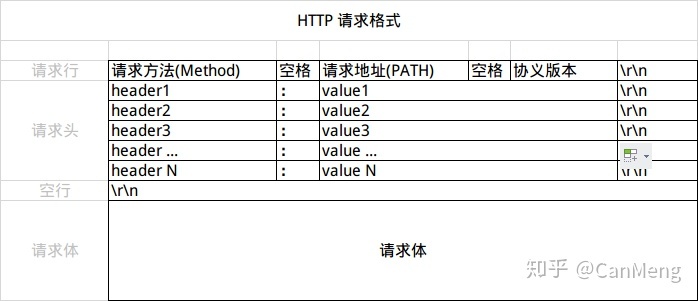
这是请求报文的一般格式。我们上一个例子没有请求体(实体体)是因为GET不需要请求体。如果是POST就需要请求体提交表单。
响应报文
1 | |
它也分为三个部分:初始状态行,6个首部行、实体体(请求体)。
初始状态行内容:
- 200 OK: 请求成功
- 301 Moved Permanently: 请求的对象被永久转移了,新的URL在响应报文的Location中
- 400 Bad Request: 一个通用的差错,表示请求不能呗服务器理解
- 404 Not Found: 表示请求的对象不再服务器上
- 505 HTTP Version Not Supported: 服务器不支持请求报文的HTTP版本
首部行内容:
- Connection close : 表示服务器将在这次传输结束之后关闭TCP。
- Date: 这里的时间是发出报文的时间
- Last-Modified: 指示对象最后修改时间
- Content-Length: 内容长度,单位是byte
Cookie
前面提到的HTTP服务器是无状态的,也就是说服务器不会对请求进行限制,所有的请求都会一视同仁的响应。然而我们经常要对用户进行限制,因此便是用了cookie。
cookie生成的大致过程为:当请求报文第一次访问这个网站时,该站点将产生一个唯一识别码,并且作为后端数据库的一个表项。接下来响应报文中就要添加一个Set-cookie项,返回生成的cookie。浏览器接收到相应报文之后,将会把cookie添加到cookie文件中。
今后访问时请求报文都会在首部行添加Cookie: …。在这种情况下,服务器就可以跟踪用户在站点的活动
Web缓存
Web缓存器也叫代理服务器。它保存着我们最近浏览的网页信息,我们可以通过配置使HTTP请求首先指向Web缓存器。
Web缓存的一般过程为
- 浏览器创建一个到缓存器的连接,并发送HTTP请求
- 如果有该对象就返回
- 如果没有就打开一个到服务器的TCP连接,发送请求
- 服务器受到请求进行处理然后发给缓存器,并且向浏览器也发送报文(通过缓存器
Web缓存器一般由本地ISP提供。例如学校和小区服务(而不是个人电脑上),因为距离非常近所以访问速度也比较快,并且可以从整体上减小因特网的流量。
但是这也会带来一个问题,缓存器中的副本不是最新的。因此为了确保内容是最新的,还有一种条件GET方法。如果报文是GET并且其中包含If-Modified-Since: 首部行,那么就是一个条件GET请求报文。
如果使用条件报文,回到原服务器中请求,如果发现服务器在指定时间后没有修改,则Web服务器向缓存器发送响应报文1
2
3
4HTTP/1.1 304 NOT Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity)
这个响应报文初始状态为304,表示该缓存器可以使用该对象,可以向请求的浏览器转发缓存的副本。正因为使用了缓存器的副本,所以相应报文中的请求体为空。
邮件传输
邮件传输大致分为3个部分: 用户代理,邮件服务器和简单邮件传输协议(SMTP)。 用户代理也就是发送邮件的网页或客户端。
每个用户在邮件服务器上都有一个邮箱(一片存储区域)。用户代理发送邮件时现发送到自己的邮箱中,然后在传输到对方的邮箱中,再传送到对方的邮件用户代理中。
邮箱中维护着一个报文队列,每隔若干分钟就会进行一次发送尝试,如果几天之后没有成功就会删除报文并且通知发送方。
SMTP
在用户代理和邮件服务器建立之后,我么就可以通过发送特定的消息(HELO, MAIL FROM, RCPT TO, DATA, CRLF等)来写邮件了。而邮件服务器接收完这些消息之后会整合成一个报文传递给对方的邮件服务器。
报文的典型格式为1
2
3
4
5From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Serching for the meaning of life.
...

但是SMTP只负责从用户本地到服务器再从自己的服务器到对方服务器,对方从服务器接受的过程不是由SMTP控制的,SMTP只能推送服务,不能拉取服务。
POP3
POP3就是负责最后从服务器到用户代理过程的。大致过程为,当用户代理打开一个邮件服务器上端口为110的TCP连接之后,POP3就开始工作了。POP3进行特许(authorization)、事务处理及更新。
- 特许: 用户代理发送用户名和口令来鉴别用户
- 事务处理: 用户代理取回报文,同时还可以对报文做删除标记或取消删除标记,还可以获得邮件统计信息。
- 更新: 用户发出quit命令后,结束POP3.之后邮件服务器将删除带有删除标记的报文。
在事务处理过程中,服务器对用户发出的命令回答有两种: +OK -ERR.特许阶段主要有两个命令: user (user name)和pass (password).
DNS
DNS是将域名转化为IP地址的过程。域名就是主机名,如www.facebook.com、www.google.com等。这些名字长度不一且没有特殊含义,只有转化为ip地址路由器才可以进行识别并且将消息传送到指定位置。
DNS主要是用UDP协议,但是在某些特殊情况下也可以使用TCP,比如跨区域传输和当一个报文大于512字节时。
使用UDP的一个重要原因是DNS报文非常小,一般只有100来个字节。而TCP建立连接就需要160个字节,销毁连接需要130个字节,而UDP只需要额外增加60多个字节。它相比于TCP有着数倍的性能提升,因此为了性能考虑一般使用UDP。
DNS构成为:
- 一个分层的DNS服务器实现的分布式数据库
- 一个使主机可以查询数据库的应用层协议,DNS协议运行在UDP上,使用53号端口
DNS通常是应用层使用的,在进行传输时首先需要将它转换为ip,大致过程为
- 用户主机上运行着DNS应用客户端(进行DNS解析)
- 浏览器从URL中抽取处主机名,并且发送给DNS客户端
- DNS客户端向DNS主机发送一个包含主机名的请求
- DNS客户端收到响应报文并发送给浏览器,浏览器再建立TCP连接
此外DNS还提供:
- 主机别名:一个主机名可以有多个别名,可以通过DNS应用程序获得别名对应的主机名和IP
- 邮件服务器别名: 和上面类似
- 负载分配: 对于某些繁忙的站点,DNS会使用多个服务器进行管理。这些服务器的IP地址各不相同,因此使用了一个IP地址集合进行管理。每次请求到来时,先用IP地址整个集合进行响应,之后每次回答中循环地址次序。这样做是因为客户总是向IP地址排在最前面的服务器发出报文。
工作机理
将所有的域名分布在各个DNS服务器中,顶层DNS负责决定给哪个服务器解析。一般来说可以将DNS服务器大致分为三层: 根DNS服务器, 顶层域(TLD)和权威DNS服务器。
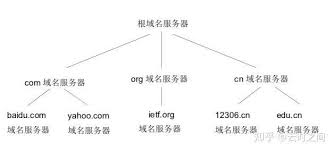
例如我们想获得baidu.com的地址。那么首先和根服务器之一建立联系,根服务器会返回com域名服务器的IP,然后根据IP找到com域名服务器再找的百度.cmo域名服务器从而找到对应IP。
- 根服务器: 大概有四百到五百根服务器遍布世界。由多个组织进行管理
- 顶层域DNS服务器: 对于每个顶层域(如com、org、net、edu、gov)和国家(uk、fr、ca、jp)都有对应的顶层域服务器
- 权威DNS服务器: 在因特网上可以给公共访问的主机都必须提供可供公共访问的DNS记录。一些组织或公司的DNS服务器收藏了这些DNS记录。个人或组织机构也可以选择支付一定费用来获得域名及在DNS服务器上添加记录。例如阿里云或腾讯云都提供了域名解析服务。
此外每一个居民区或机构的ISP都有DNS服务器,称为本地DNS服务器本地DNS服务器负责与上面三种服务器进行交互并传递数据。
大体上可以分成两种搜索方式:
- 迭代查询: 当主机向DNS提出请求时,如果不在这个dns服务器上,他不提供结果,而是提供另外一个可能提供结果的服务器地址,然后主机根据这个地址进行查找
- 递归查询: 主机向服务器提供请求时,如果不在这个dns上,他会询问其他服务器,并且将查找结果给主机
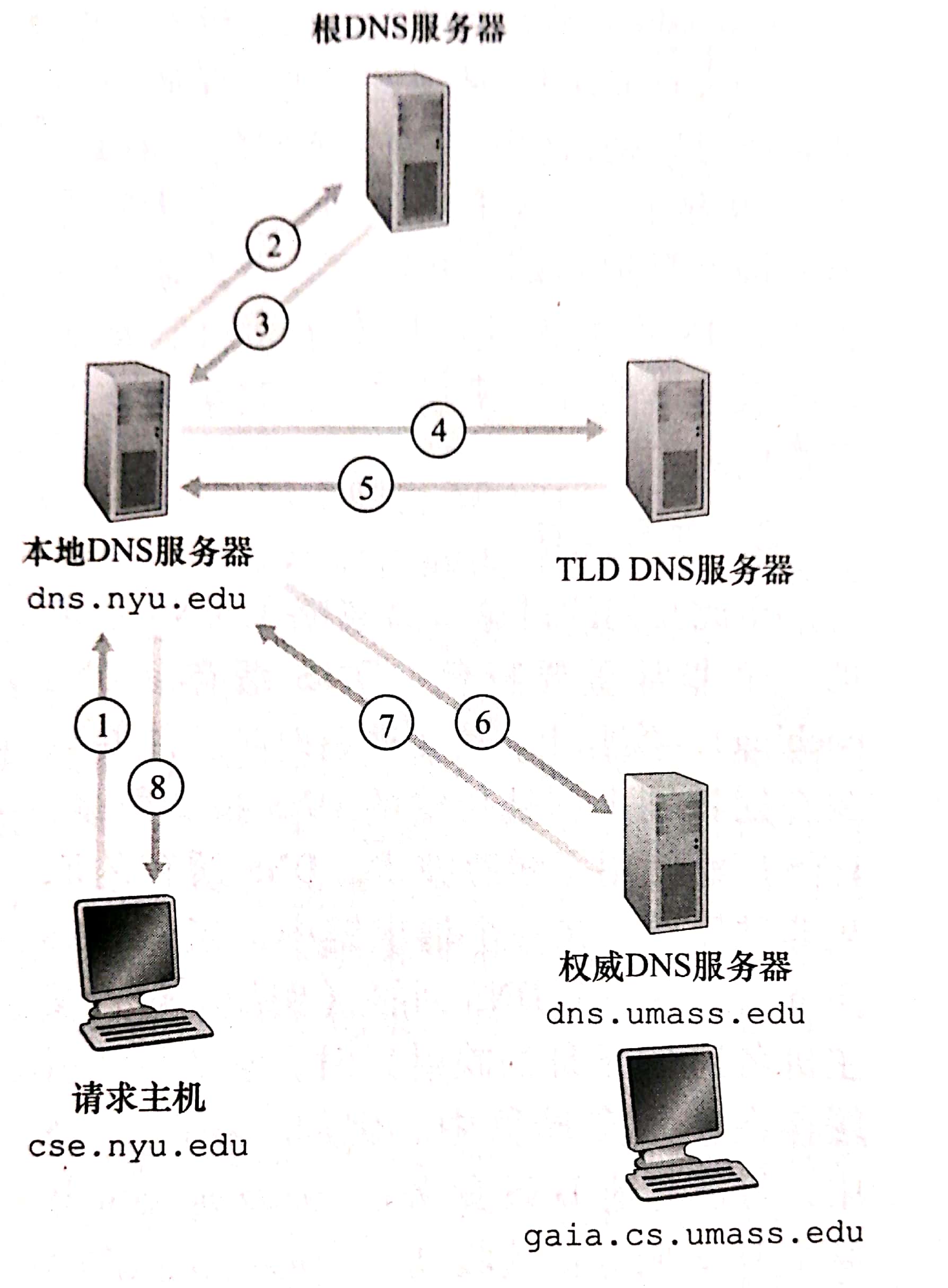
以上是添加了请求主机后的过程。1-8表示过程先后顺序。主机到本地dns是递归查询,其他的都是迭代查询
实际上除了这种方式之外还有另外一种方式,这种方式全是递归查询。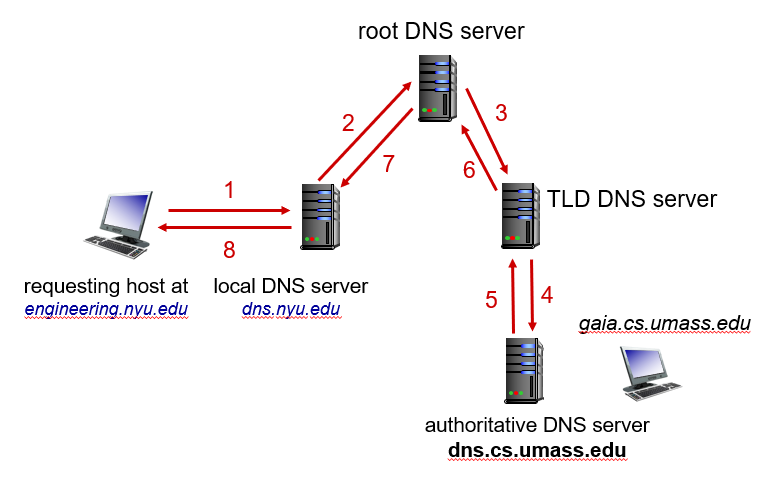
DNS缓存
DNS缓存原理非常简单,就是每次请求完成之后保存一份在本地DNS服务器中,每次进行DNS解析时首先到本地服务器中寻找。
DNS缓存时间是有限的,一般是两天。
DNS记录和报文
DNS数据库中存储了资源记录(RR)。每个DNS回答报文中包含一条或多条资源记录。
资源记录是一个四元组:
(Name, Value, Type, TTL)
- TTL: 该记录生存时间,也就是应当从缓存删除的时间
- 如果Type=A,则Name是主机名。Value是该主机名对应IP(abcd.com, 145.37.93.126, A)就是一条A记录
- Type=NS, 则Name是域。 Value是存储着转换信息的权威DNS服务器主机名。例如(foo.com, dns.foo.com, NS)
- Type=CNAME, Value是别名为Name的规范主机名。例如(foo.com, dns.foo.com, NS), (xinhecuican.tk, xinhecuican.github.io, NS)
- Type=MX, Value是别名为Name的邮件服务器的规范主机名。(foo.com, mail.bar.foo.com, MX)
如果DNS服务器是用于特定主机名(TLD)的权威DNS服务器,那么它就会包含一条TLD的A记录。如果不是用于主机名, 那么还要记录包含主机名的域的NS记录。
例如 一台eduTLD不是gaia.cs.umass.edu的权威服务器,那么该服务器将包含一条cs.umass.edu的域记录,如(umass.edu, dns.umass.edu, NS),然后还有一条A记录,如(dns.umass.edu, 128.119.40.111, A). 也就是说可以通过这台eduTLD找到对应的用于解析的服务器。
DNS报文
DNS查询报文和回答报文有相同的格式
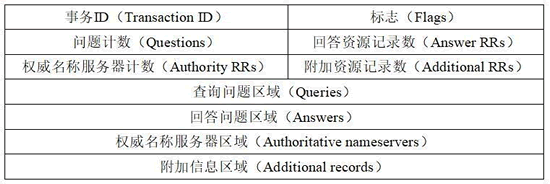
- 前12字节是首部区域
- 事务ID(标识符)用于标识该查询,占2字节。他会被复制到回答报文中。
- 标识: 1bit的标识位指出是查询报文(0)还是回答报文(1)。权威标志位会在权威DNS服务器的回答报文中置1. 希望递归标志位会在DNS服务器支持递归查询时置1.
- 四个其他字段: 用来表示后面四个部分的数量
- 问题区域: 包括
- 名字字段: 正在被查询的主机名
- 类型: 正在询问的类型。例如A,NS
- 回答区域: 也就是前面说的资源记录,这里可能有多条
- 权威区域: 包含其他权威服务器的记录
- 附加区域: 一些附加信息
向DNS服务器中插入记录
有许多域名登记机构负责插入记录,他们会收取少量费用(几元到几十万不等)。
例如我们向登记机构注册networkutopia.com时,需要想机构提供基本和辅助权威DNS服务器的名字和IP。例如dns1.networkutopia.com, 212.212.212.1和dns2.networkutopia.com, 212.212.212.2。对于这两个权威DNS服务器,注册机构都会向其中添加一条NS和一套A记录输入TLCcom服务器。然后将下面两条资源记录插入DNS数据库中1
2(networkutopia.com, dns1.networkutopia.com, NS)
(dns1.networkutopia.com, 212.212.212.1, A)
此外,还有确保自己网站的A记录和MX记录被输入到权威DNS服务器中。
P2P
一般的文件分发模式是服务器-客户模式,也就是客户上传到服务器,服务器来进行发送。而P2P模式在用户接收到文件之后可以给其他用户发送。与传统的客户-服务器模式相比,P2P模式可以更好的应对大流量。
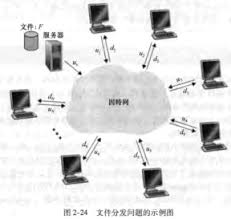
如图, 服务器上传速率为$u_s$,第i个要文件的电脑下载速率为$d_i$,上传速率为$u_i$.F是文件大小
最小分发时间>= max{N * F / $us$, F / $d{min}$ }
其中N * F / $us$是服务器传输所有文件所需要的时间,而F / $d{min}$是用户下载需要的最少时间。可以看为每多一个用户就需要占用一份服务器的上传速率,如果它占用的上传速率小于自己的下载速率那么限制因素就变成了第一个。
因此如果用户非常多,这种模式下服务器负载非常大,对每个用户来说服务器上传速率也就很低了。
P2P模式
- 首先只有服务器有文件。它先将文件中的每个字节发送到各个用户上。所需时间为F/$u_s$
- 之后用户也可以通过自己接收到的部分参与分发。总的上传速率为$u{total} = u_s + u_1 + … + u_n$。它现在的最小分发时间变为 max{F/$u_s$, F/d{min}, N*F/$(us + \sum{i=1}^{N}u_i)$}
BitTorrent
BitTorrent是一种P2P协议,BitTorrent把所用下载用户称为洪流(Torrent),在洪流中彼此下载等长度的文件块。如果一个用户下载完成它可以选择退出洪流或者继续共享。
具体的说,每个洪流都有一个基础节点,称为追踪器(tracker)。每当一个下载用户加入时,他都会向追踪器申请注册并且周期性通知它仍在洪流中。
在被加入到追踪器后,追踪器会让他参与一个洪流的子集(例如50个用户),并且把这些用户的IP发给该用户。然后该用户就会按照IP创建TCP连接,创建成功则称对方为对等方。
该用户会周期性的询问邻居他们所具有的块。邻居会发一个他们所具有的块列表,然后该用户会根据表来请求没有的块。
请求块依据最稀缺优先,也就是请求邻居中拥有数量最少的块。
CDN和视频内容分发
视频
在HTTP中,视频只是一个文件,可以通过一个URL和一个TCP连接得到。当获得的字节到了一定阈值之后,视频就开始播放,与此同时后台还在继续获取并缓存。
但是有些人的带宽小,有些人的带宽大,如果只有一种分辨率,难以满足所有人的需求。因此产生了HTTP的动态适应性流(DASH)。在DASH中,视频被编码为不同版本,并且有一个告示文件高速了各个版本的地址,用户首先申请告示文件然后再申请对应版本的视频。
内容分发网(CDN)
传统的视频提供会遇到一些问题。因为对于因特网视频公司,提供视频最直接的方法时建造数据中心,然后进行分发。但是这样当遇到距离遥远的客户时就可能因为某个服务器速度的限制导致传输速率非常低。其次重复数据可能多次经过相同链路分发多次,造成资源浪费。最后如果数据中心出现了某些故障那么将不能分发视频。
为了解决这些问题,视频供应商使用了内容分发网(content distribution network, CDN).CDN管理多个地理位置上的服务器,并且存储视频或其他内容
CDN操作
CDN具体操作为
- 通过DNS截获特定的URL
- 查找对应的CDN服务器
- 重定向到对应服务器
例如: NetCineama想让KingCDN来替它分发视频。首先NetCinema的每个视频的URL都有video。例如: http://video.netcinema.com/6Y3B32V.接下来
- 用户点击链接并且本地DNS服务器向NetCinema请求IP。该权威服务器发现主机名中有video。为了将该DNS请求给KingCDN,NetCinema返回一个KingCDN的主机名,如a1105.kingcdn.com
- 本地服务器继续发送请求,在KingCDN中返回CDN服务器的IP
集群选择策略
前面说了CDN是分布式的。也就是说虽然定向到了CDN的权威服务器但是返回的IP不同最终速度也会大不相同。因此选择集群是非常重要的。
一种方式是地理上最为临近的集群。每个本地DNS服务器都有一个地理位置,DNS权威服务器返回离他最近的DNS服务器。但是地理距离近不等于网络距离近,还是要看经过的ISP数量。
另一种方法是进行周期性的实时测量。例如每隔一定时间就向全世界所有本地DNS发送合租来探测速度,但是可能本地DNS不会响应这些探测。