KNN算法
本文最后更新于 2020年7月22日 晚上
大致步骤
KNN是最临近规则分类算法。
为了判断未知分类,我们需要用已知分类进行参照。
- 选择参照物个数k。 k的取值一般都比较小,可以是1,3,5,7等数,通过实验得知哪个比较好就用哪个。一般用奇数,避免两边数目相同
- 选择最近的k个实例然后看他们都属于哪个类,让这个实例成为数目最多的实例。
距离衡量方法
- EUclidean Distance方法。和距离公式类似,对应特征值相减平方再开根号。
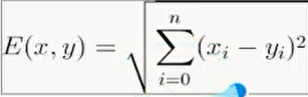
例:
1 | |
本文最后更新于 2020年7月22日 晚上
KNN是最临近规则分类算法。
为了判断未知分类,我们需要用已知分类进行参照。
距离衡量方法
例:
1 | |