储存设备与缓存
本文最后更新于 2025年3月25日 下午
机械硬盘
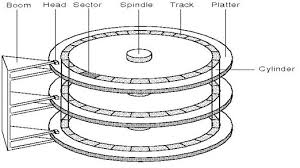
结构: 由若干个盘片组成,每个盘片有2两面,每一面上有若干个磁道(柱面就是指和中心轴平行的圆柱面,有多个每个盘上都有两个磁道在上面) ,每个磁道上又划分成若干个扇区,扇区是数据访问的最小单位。中间的轴在不停转动。每个扇区都有一个编号。
显然如果扇区划分时是从中心发出多根射线的话是不好的。因为内圈的扇区划分小,外面的扇区划分大,因此每个扇区读写数据数目可能会有较大的差距。但是很可能只需要利用其中很小一部分,这样就造成了浪费。所以磁道与磁道之间扇区数目是不同的,尽量使数据分布均匀。
图中左边的架子是读写头,可以前后滑动。数据就是通过读写头进行读写的。
大致过程:先移动到对应扇区(寻道),然后等待读写头划过我们要读取的扇区。之后在读取这个扇区。要注意即使只需要读取一个字节也要把这个扇区全部读取完。如果是写的话,先把扇区中数据读取出来,然后再在这些数据中进行更改,最后再把这些数据写入到扇区中。
一般寻道在2-9ms,旋转也是10ms左右,而读取只需要0.02ms,所以说大头都在寻找过程中。并且要比dram慢2500倍,比sram慢40000倍。
旋转时间如果没有特殊规定一般都是算旋转半圈的时间,而读取时间一般使用旋转一圈时间/扇区数得到
机械硬盘扇区的读取次数是由限制的,大概是十万到100万次左右。如果某一扇区坏了是不是会导致整个硬盘都异常呢?当然这是不可能的,那样也太不经用了。
为了解决这个问题,可以用逻辑编号代替物理编号,然后用一定的映射规则转换到物理编号,如果某一个扇区损坏,硬盘中有一些备用的扇区可以替补上,这样就可以解决某一个扇区损坏的问题。可能某些逻辑扇区会被频繁的使用,如果对应规则是确定的那么可能很快那个扇区就会损坏,所以对应规则也要不断变化使每个扇区利用大致平均。
寻道算法
- FCFS(先来先服务): 这种算法就是先来的请求先服务。但是固态采用的是这种算法(因为不需要考虑寻道时间)
- SSTF(最短位置优先): 这种算法是在所有请求中找到距离他最近的
- SCAN(电梯算法): 先一直朝着某个方向走,这个方向没有之后再往反方向走,这种在实际中有应用
- CSCAN(循环电梯算法): 这种方法时一直朝一个方向走,到了顶部又直接放回底部重新扫描
例:现在在15磁道。请求有81, 47, 90, 18, 5.并且现在向上走
FCFS: 15->81, 81->47, 47->90, 90->18, 18->5
SSTF: 15->18, 18->5, 5->47, 47->81, 81->90
SCAN: 15->47, 47->81, 81->90, 80->18, 18->5
磁盘RAID
磁盘RAID是在逻辑卷出来之前为了多个磁盘同时使用而想出来的算法。首先要求这些磁盘大小相同
条带化: 条带化指的是将一个数据分成多个部分写入不同的磁盘的机制。RAID0就是用了这种机制。
缓存: 和下面将的回写类似
奇偶校验: 将数据奇偶校验信息放到不同磁盘上。奇偶校验信息是这个数据的0的个数或者1的个数。RAID5使用了奇偶校验
磁盘镜像: 指的是将磁盘内容复制到领一块磁盘中,这样一块磁盘损坏还可以使用领一块磁盘。RAID1使用了磁盘镜像
奇偶校验和磁盘镜像可以提高RAID可靠性。条带化和缓存提高速度。
RAID0
RAID0就是将一个文件拆分成多个部分,然后同时写和读。但是有一个相当大的问题是如果一个磁盘坏了那么所有文件都坏了。
RAID1
RAID1是从一个极端到了另一个极端。例如有两份磁盘,那么他将把一份数据写到两份磁盘中。这样写的效率毫无疑问是低的,但是读的效率还行(因为可以两个磁盘同时读),并且浪费一半的空间
RAID10
RAID10并不是10而是RAID1和RAID0的组合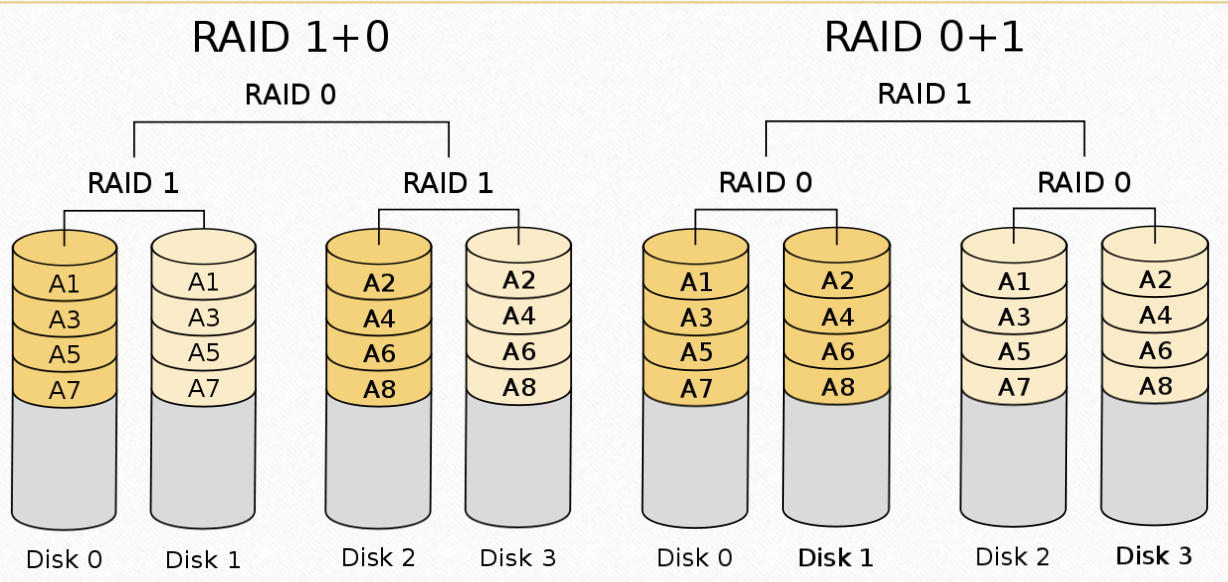
这种兼顾读写效率和可靠性,但是同样要浪费一半的空间
RAID5
RAID5是现在一般使用的技术。RAID5同样是把一个文件拆分成多个文件写(一般是以块为单位拆分)。但是现在每个磁盘都储存着其他磁盘文件的恢复信息。例如2磁盘存着1磁盘的信息,3磁盘存着2磁盘的信息。这样如果一个磁盘损坏另外的磁盘还可以恢复信息。
会浪费一块磁盘的空间
RAID4
RAID4是单独拿一块盘出来保存一些恢复信息,但是这样如果校验盘坏了就非常危险。
RAID6,7等
市面上说的RAID6就是多出一块盘来做备用,如果一块盘坏了这块盘立刻读取恢复信息并工作。这实际上是RAID5。实际上是有RAID6的技术的,但是一般不采用
总结
固态硬盘(ssd)
结构: 固态硬盘最小的结构是页,每一页有若干个字节。之后若干个页组成了块。它是由闪存构成的(就是usb所使用的)
读写过程:读的过程是以页作为单位,也需要通过一定的映射使之利用均衡。但是写的过程却是以块作为单位,就算只改一个字节也需要读取整个块,并且写的过程中需要先把原来的内容全部擦除,所以写过程比读过程慢的多。
ssd好处是读写较快,但是价格贵,并且读写次数少,只有1万到10万次。
局部性和高速缓存
局部性分为时间局部性和空间局部性。
时间局部性指的是在短时间内多次重复使用某个内存。
空间局部性指的是一个内存被使用,很可能接下来会使用这段内存附近的数据。
现代计算机cpu运算速度已经很快了,但是内存的访问速度却跟不上cpu的运算速度。因此现在更重要的是解决内存读取速度的问题。
根据上面所说的局部性原理(这是人们通过大量观察总结得出的规律),人们想到可以把常用的数据放在一个更快的储存器里,这样就可以提高运算速度。
于是就有了高速缓存。高速缓存(cahce)是用sram制成的,它的速度很快但是容量很小,直接集成到了cpu内部,每次cpu访问内存的时候都会先从高速缓存中读取。如果高速缓存中没有才会去内存中查找。从内存中取出数据并不是只取那几个字节,而是把附近的指令都放到高速缓存中(因为局部性原理),这样就可以提高速度。
高速缓存运行原理
基本结构
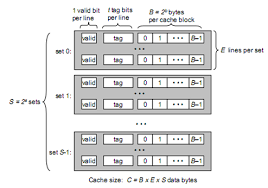
一共有S个组,每个组有E行,每行有B个字节。S,E,B都是2的n次方,记S是2的s次方,E是2的e次方,B是2的b次方。
每一行的B字节都是由三部分组成。最高位叫做有效位,用来判定这一行中是否储存了数据。之后又t字节标记位,用来进行判别,后面的位才是实际从内存中取出来的内容。
每次cpu访问一个地址时,可以把地址分成3个部分。最低b位是块偏移,中间s位是组索引,高t位是标记。
进行查询时,先用中间s位找出组索引。例如中间s位是010,那么组索引是2.找到组索引后就用高t位的标记进行比对,如果对应行中最高位为1且标记位正好符合那么就通过最后的b字节找到块偏移。然后取出数据。
注意,我们只需要找到对应的组就行了,cpu可以自动对该组所有行同时进行比对而不用一一比对。
例 cpu发出一个指令,要从0111位置取出两字节数据。首先高速缓存中有四组,每组一行。每行四字节。所以这里块偏移是1组索引是11,标记是0.那么我们先通过中间的11确定是第三组,之后再和第三组最高位为1的进行比对,如果有一行标记位正好是0,那么就算出偏移量是1,所以从后面开始的第一位(有第零位)取出两个字节。
直接映射高速缓存
直接映射高速缓存的特点是每一组只有一行。所以找到组后直接进行比对即可。但是这里有一个问题,例如组索引是1,标记位有两位。那么可能频繁的取出组索引相同但是标记位不同的数据,那么我们就要频繁的从内存中取出数据(miss),这样就降低了速度。
组相联高速缓存
组相联高速缓存和直接告诉缓存的不同是组相联高速缓存中每一组有多个行,这样就更可以存放更多的标记位,miss的可能性也就越低。但是这个的问题是因为要同时访问多行,所以硬件设计比较困难。
全相连高速缓存
全相连高速缓存中只有一个组,因此没有组索引(想要有组索引最少要有两个组)。
因此把cpu发送的内存地址分成两个部分,块偏移和标记。因为没有组索引,所以这两部分一般比较大。它可以同时匹配所有的行,也就少了寻找组索引的计算,但是如果行太多设计极为困难,所以只适合做小的高速缓存。
直写与回写
直写就是每次都要写到内存或者硬盘中,回写就是每次先在缓存中写,等到这个缓存被替换的时候再写回。毫无疑问回写要快,但是直写也有用武之地。
块替换策略
每次未命中时并且缓存中已经全部使用的时候就要进行块替换。块替换有两种策略,第一种是把最近没有使用的块替换出去,第二种是把最不经常使用的块替换出去。
cache结构影响
如果我们固定容量,将cache的cache每一块的大小增大的影响为:
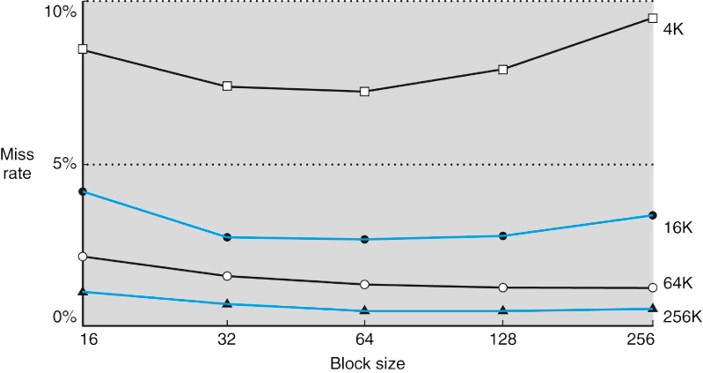
块大小比较小时增大缓存可以减小冷启动带来的影响(强制缺失),但是当块太大导数块的数量减少从而导致冲突缺失增多。
如果我们增大相连度,它的曲线为: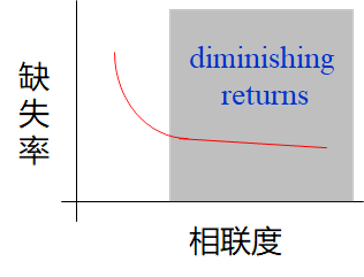
可以看到增大相连度到一定程度后对性能的改善将不再明显,并且还会导致硬件设计的复杂程度升高从而导致性能降低。一般相连度超过8带来的增益将不再明显。
缓存改进
victim cache
在L1级缓存和L2级缓存之间添加一个小缓存,一般只有3-16个cache行,当L1的块被替换时先存在victim cache中,具体工作方式为:
- 当L1cache替换时,vc保存该快
- L1缺失时,首先从vc中寻找
- vc命中时将vc的对应块放到L1中,并且将L1替换下来的块放到空出来的位置中
vc给人一种组相连的错觉,它针对解决直接相连冲突严重的问题,那么只有一个cache行也会有极大改善
预取机制
预取机制是提前将主存装入cache,它通过提升未来访问Cache的命中率来隐藏访存延迟。它在被预取的主存块被访问前装入cache最好。
- 顺序预取器: cache缺失时,除了读当前块,还要读下一块
步幅预取器: 因为循环操作中会频繁访问内存,而循环操作有一定规律,我们可以根据规律来进行预取
为了实现步幅预取器,我们可以使用引用预测表(RPT),它有若干个表项,每个表项对应一条访存指令,每个表项由四项组成:- tag: 用于检索表项(pc检索)
- address: 记录上次访存地址
- stride: 记录两次访存之间的步长
st: 状态预测机
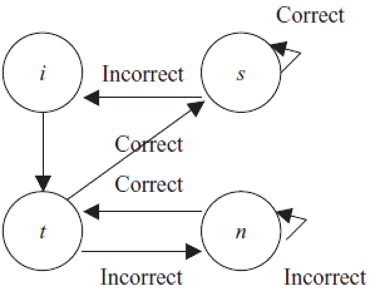
- i: 初始状态,会自动跳转到下一状态
- t: 如果当前访存的stride=表项中的stride,则表明出现了流访存模式,状态变为s,并且开启预取,预取地址为当前地址+stride。此外还需要判断当前预取块是否在cache中,如果在则取消预取。如果stride不等则跳转到n状态,并且更新address和stride
- s: 如果访存的stride还是表项中的stride,只更新address。否则转态跳转到i,并且更新address和stride
- n: 不触发预取,但是每次仍计算stride,如果发现stride相等则跳转到t状态
预取可能带来的问题:
- cache污染: 因为不准确的预取可能将有用块替换成无用块。可以将预取送到一个缓存中
- 带宽占用: 预取访存流不能影响正常的访存流,需要给予正常访存流更高的优先级
多级cache
多级cache有两种:
- 包含式cache: L1的数据一定在L2中
- 独占式cache: L1和L2中的数据不重叠
包含式cache替换过程:
如果L1和L2都Miss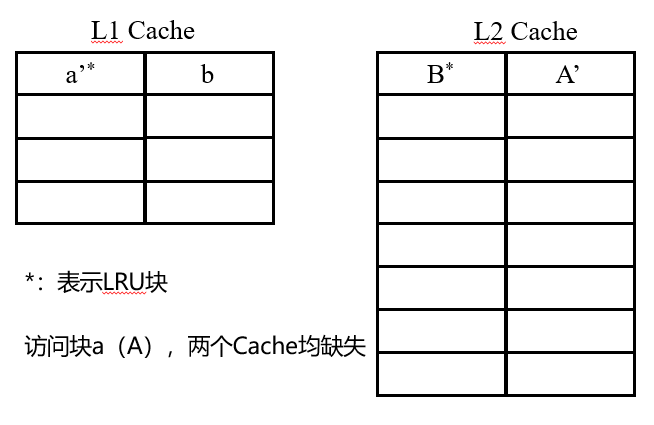
如图所示,现在需要读取a(A),a和A都是一个块,大写表示它在L2中
- 首先访问到L2,发现没有A,因此这时就需要从主存读a了,也就是说B将被替换掉
- 由于B将被替换掉且这是包含式cache,因此需要将b也换下来,如果b是脏数据则需要先将b写回B然后将b置为无效再将B替换。否则直接替换B
- 然后将A放到原来B的位置,由于此时是lru块,因此还需要将替换下来,最后a在的位置上
写缓存
写操作时cpu其实可以做其他事,不需要等待主存操作完成。

如图所示是写缓存的结构,当我们有写需求时放入写缓存中。
当我们先写后读同一个地址时可能会出现问题。因为此时写的数据可能还在缓存中,这时我们直接读L2可能不是最新的数据,因此需要和写缓存的数据进行比较。

非阻塞cache
有时候多个读指令的地址是连着的,因此实际上只需要读取一块就可以满足几条指令的需求。这时我们可以缓存读操作,判断这几个操作是否是同一个cache行。

如图所示是一个cache行对应的MSHR表结构,他的字段含义如下:
- B: 是否还有空闲位置,如果没有则先阻塞
- Line addr: 表示当前是哪个cache行
- Line offset: 行内偏移
- Dest reg: 目标寄存器
- Format: 表示当前是读字,半字或者字节