LLBP
本文为The last-level branch predictor的阅读笔记
context局部性
- context: 每两个无条件分支之间的指令为一个context
- pattern(模式): 该分支在不同的分支历史下会有不同的结果,每一种分支历史对应的结果称为一个模式。例如从不同位置调用某个函数时该函数内的分支可能有多种行为。如果某个历史长度下该模式提供了正确的预测,更短的历史长度便预测错误,那么称该模式为一个有用的模式。
观点:
- 如果某一个分支模式越多,那么他所需要的分支历史也越多
- 如果一个分支有多种模式,那么一个给定上下文只对部分模式有用
发现:
- 前十难预测分支的模式中平均分支数量为200
- 两个无条件分支之间平均包含3.89个条件分支。也就是说一个长度为200的分支将跨越50多个无条件分支
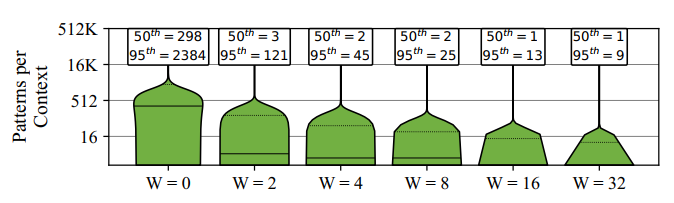
- 当上下文大小为2时,50%的分支每个上下文中包含3个有用的模式,当上下文大小为32时,95%的分支每个上下文中包含9个有用的模式。这说明我们可以将每个上下文中的模式限制在少数几个,这称为上下文局部性。
结构
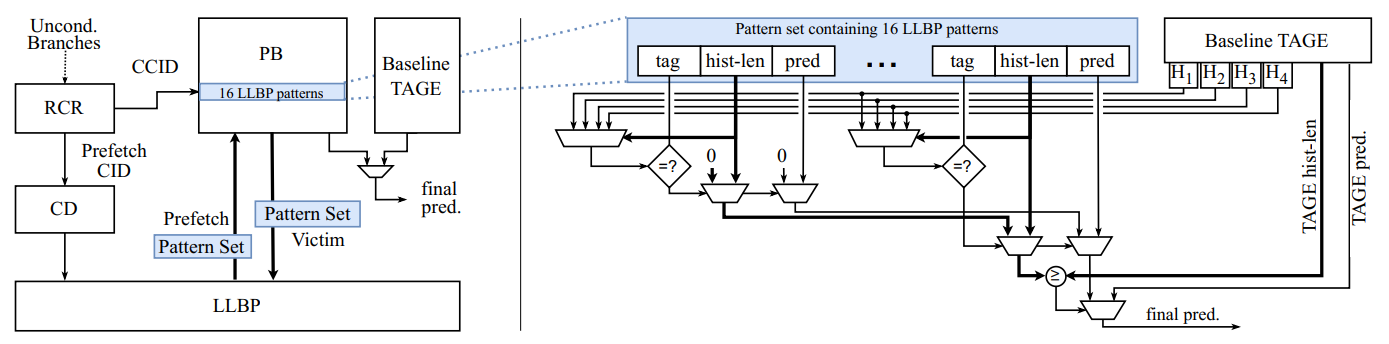
- RCR(rolling context register): 维护无条件分支的地址,用来计算当前上下文ID(CCID)。它使用队列结构,包含若干过去的无条件分支。
- CD(context directory): 存储元数据的表,包含valid, tag, pattern set storage location, replacement metadata。它保存了LLBP的元数据
- PB(pattern buffer): 存放了当前和N个过去上下文的模式集。还存放一个预取的模式集。PB是LLBP的缓存,用于提高获得模式集的速度。
- LLBP:相当于L2Cache,用来存储被替换出去的模式集
每个存储在PB中的模式包含:
- tag
- ctr
- hist_len: 用来构建pattern tag的全局历史长度
预测
预测过程:
- hist_len有若干选择,计算每个选择对应历史长度的tag,同时使用CCID查表
- 使用hist_len选择对应的tag,并且和PB中的tag进行匹配,如果匹配成功则选择
- 将LLBP中的结果和TAGE的结果放在一起进行选择,最终选择历史长度最长的
PCID
当模式集不在PB中时需要从LLBP中获得,这增加了额外的时延,文中使用PCID(prefetch CID)来从LLBP中预取数据。
PCID需要提前于CCID的数据进行计算,一种方法是对未来的无条件分支进行预测,这种方法会引来额外的预测失误。文中提出使用更老的无条件跳转地址来计算CCID。
例如RCR存储了n条过去的无条件跳转地址,计算CCID时使用[n-1: 2], 计算PCID时使用[n-3: 0],如此来实现CCID和PCID同时计算。
更新
- 预测正确:更新提供预测部件的ctr(和TAGE更新过程类似)
- 预测错误:无论是TAGE还是LLBP预测错误都会进行如下步骤
- 如果当前上下文不在LLBP或PB中,将CCID写入CD并且构造一个新的模式集写入PB和LLBP。写入PB时会触发PB和LLBP的替换,LLBP的替换根据CD中的replacement bits。其中pattern的hist_len是tage中被更新表的index。例如TAGE中第三个表被更新,那么构造一个hist_len=3的pattern插入模式集中。
- 如果PB有效,那么低置信度的模式将被替换。并且所有模式还需要按照历史长度从小到大排序。为了提供排序的速度,还可以对pattern进行分组,比如说pattern 1-4的历史长度为12-54。这样不仅可以增加排序速度还可以减少hist_len位数
需要注意的是在代码中它的更新和TAGE紧密相连,只有TAGE申请表项的同时才会在LLBP和PB中申请表项。
LLBP
https://www.xinhecuican.tech/post/46b3e955.html