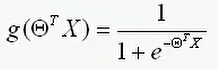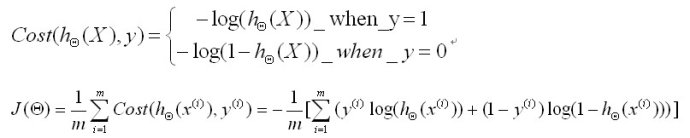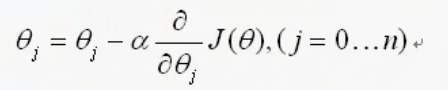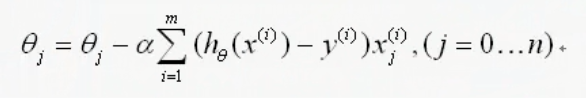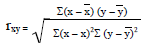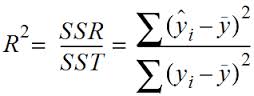本文最后更新于 2020年7月29日 上午
逻辑回归(logistic regression) 非线性回归例子:
sigmoid函数图像为
所以预测函数为:
我们要求解的问题可以转化成,求解一组参数使得J()最小化。求解方法时求偏导让导数为零。
当然上面这个方法求解过于复杂,我们也可以使用梯度下降的方法。非线性方程其实就是一个超平面,我们可以求偏导找出梯度,沿着梯度下降的方向不断走就可以找到最低点。
求解函数为
其中a是更新率(learning weight)
所以求完偏导的结果为:
h(x) = theta * x(i)
这就是更新函数,我们呢需要重复更新直到 收敛
实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import numpy as npimport randomdef genData (numPoints,bias,variance ):2 ))for i in range (0 ,numPoints):0 ]=1 1 ]=i0 ,1 )+variancereturn x,ydef gradientDescent (x,y,theta,alpha,m,numIterations ):for i in range (numIterations):sum (loss**2 )/(2 *m) print ("Iteration %d | cost :%f" %(i,cost))return theta100 , 25 , 10 )print "x:" print xprint "y:" print yprint ("m:" +str (m)+" n:" +str (n)+" n_y:" +str (n_y))100000 0.0005 print (theta)
使用线性回归还是非线性回归 在高中已经学过了,如果是一元线性回归的话会使用相关系数r来描述相关性,来决定是否使用线性回归。它的公式是
如果是多元线性回归就要用
这个公式中第一个yi是估计值,也就是说先要把回归方程求出来再估计相关性。
但是R^2会受样本量影响,随样本量增大而增大,所以要一个小小的改进。
这个方程就是改进后的方程,先把开始的R^2算出来,然后带入,其中N是样本个数,P是维数(自变量个数)
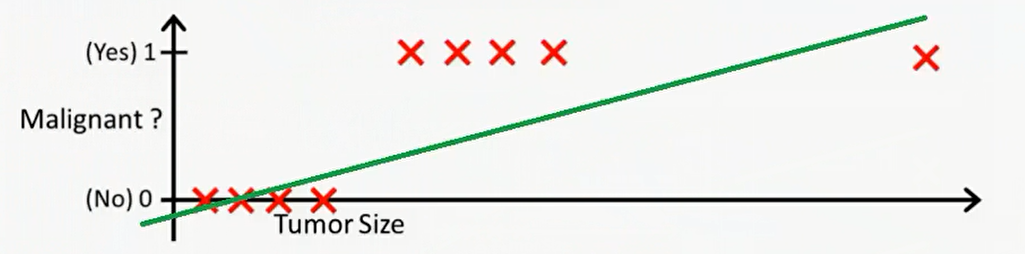 .这个例子中的关系不能很好的用线性关系进行模拟,所以我们要另外做曲线模拟它。
.这个例子中的关系不能很好的用线性关系进行模拟,所以我们要另外做曲线模拟它。 为了更好的处理,还需要用sigmoid函数平滑化。
为了更好的处理,还需要用sigmoid函数平滑化。